«`html
Автоматическое распознавание речи (ASR) в искусственном интеллекте
ASR стало ключевой областью в сфере искусственного интеллекта, фокусируясь на способности транскрибировать устную речь в текст. Технология ASR широко используется в различных приложениях, таких как виртуальные ассистенты, трансляция в реальном времени и голосовые системы. Эти системы являются неотъемлемой частью взаимодействия пользователей с технологией, обеспечивая управление без использования рук и улучшая доступность. По мере роста спроса на ASR возрастает и необходимость в моделях, способных эффективно обрабатывать длинные речевые последовательности с высокой точностью, особенно в реальном времени или потоковых сценариях.
Вызовы ASR систем
Одной из основных проблем с ASR системами является их способность эффективно обрабатывать длинные речевые высказывания, особенно на устройствах с ограниченными вычислительными ресурсами. Сложность моделей ASR увеличивается с увеличением длины входной речи. Например, многие текущие системы ASR полагаются на механизмы самовнимания, такие как мультиголовное самовнимание (MHSA), которые захватывают глобальные взаимодействия между акустическими кадрами. Хотя эти системы эффективны, они имеют квадратичную временную сложность, что означает, что время, необходимое для обработки речи, растет с увеличением длины входа.
Решения для повышения эффективности
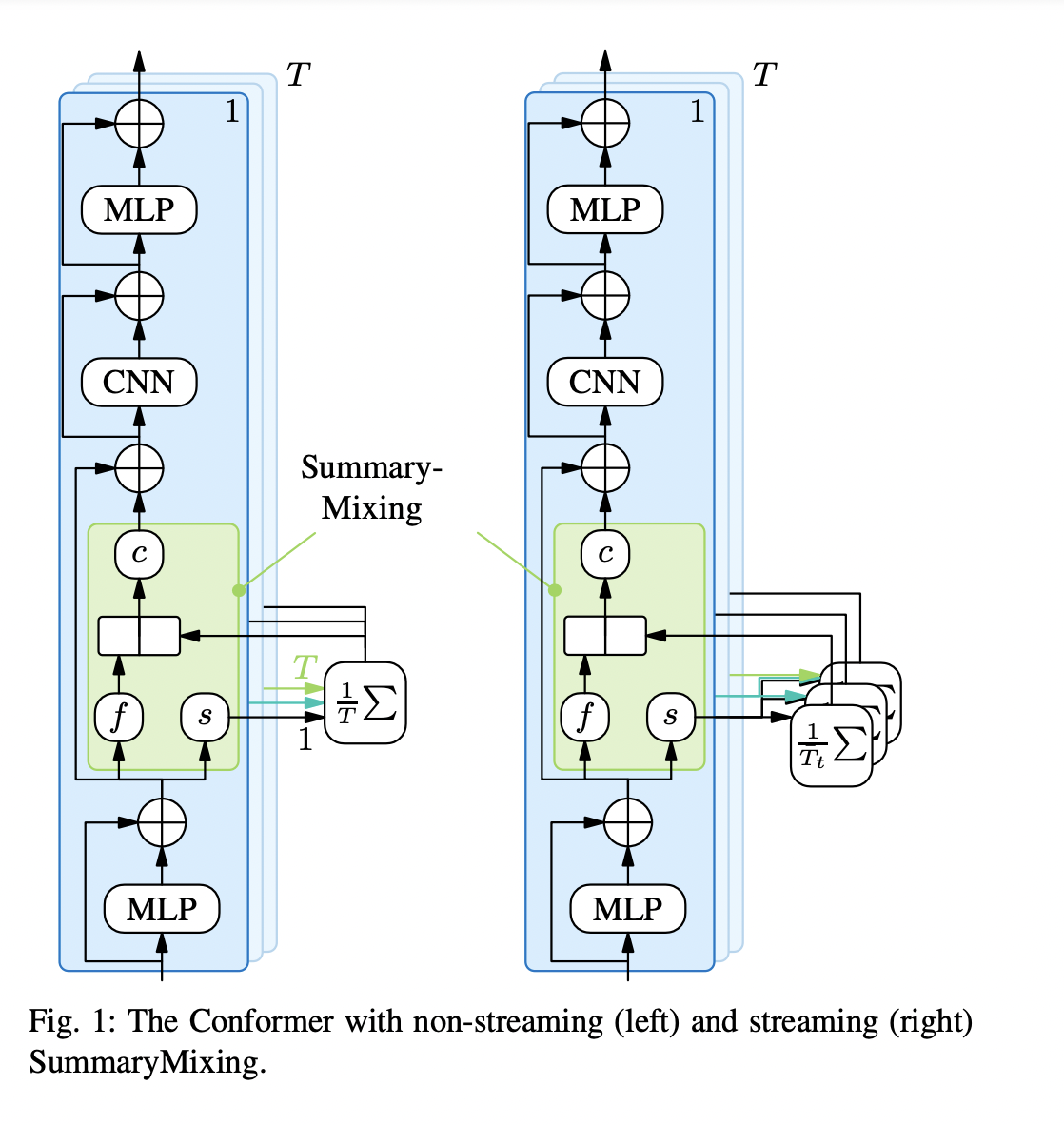
Были предложены несколько методов для снижения вычислительной нагрузки систем ASR. Одним из таких методов является SummaryMixing, предложенный исследователями из Samsung AI Center – Cambridge. Этот метод позволяет значительно улучшить эффективность conformer-трансдьюсера, особенно в реальном времени. SummaryMixing заменяет MHSA более эффективным механизмом, который резюмирует весь входной набор данных в один вектор, что позволяет модели обрабатывать речь быстрее и с меньшей вычислительной нагрузкой.
Практическое применение
SummaryMixing представляет собой значительное совершенствование технологии ASR путем улучшения механизмов самовнимания за счет снижения временной сложности от квадратичной до линейной. Этот метод значительно улучшает обработку речи и снижает потребление памяти, делая его подходящим для использования в ресурсоемких средах.
«`

























