Улучшение больших языковых моделей с разнообразными данными для обучения: подход к кластеризации и итеративному совершенствованию
Практические решения и ценность:
Большие языковые модели (LLM) стали ключевой частью искусственного интеллекта, позволяя системам понимать, генерировать и отвечать на человеческий язык. Эти модели используются в различных областях, включая естественное языковое мышление, генерацию кода и решение проблем. LLM обычно обучаются на огромных объемах неструктурированных данных из интернета, что позволяет им развивать широкое языковое понимание. Однако для улучшения их специфичности для задач требуется доводка, чтобы согласовать их с человеческим намерением. Доводка включает использование наборов данных с инструкциями, состоящих из структурированных пар вопрос-ответ. Этот процесс важен для улучшения способности моделей точно выполнять задачи в реальных приложениях.
Растущая доступность наборов данных с инструкциями представляет собой ключевую проблему для исследователей: эффективный выбор подмножества данных, улучшающего обучение модели, не истощая вычислительные ресурсы. С увеличивающимися наборами данных, содержащими сотни тысяч образцов, сложно определить, какое подмножество оптимально для обучения. Эту проблему осложняет тот факт, что некоторые точки данных вносят более значительный вклад в процесс обучения, чем другие. Необходимо не только полагаться на качество данных, но и достичь баланса между качеством и разнообразием. Приоритет разнообразия в обучающих данных обеспечивает эффективную обобщенность модели по различным задачам, предотвращая переобучение на конкретные области.
Текущие методы выбора данных обычно сосредотачиваются на локальных особенностях, таких как качество данных. Например, традиционные подходы часто фильтруют низкокачественные образцы или дублируют экземпляры, чтобы избежать обучения модели на неоптимальных данных. Однако этот подход обычно игнорирует важность разнообразия. Выбор только высококачественных данных может привести к моделям, которые хорошо справляются с конкретными задачами, но требуют помощи для более широкой обобщенности. В то время как выборка с учетом качества использовалась в предыдущих исследованиях, она не обладает глобальным представлением обобщенности всего набора данных. Более того, ручные наборы данных или фильтры на основе качества требуют много времени и могут не уловить полную сложность данных.
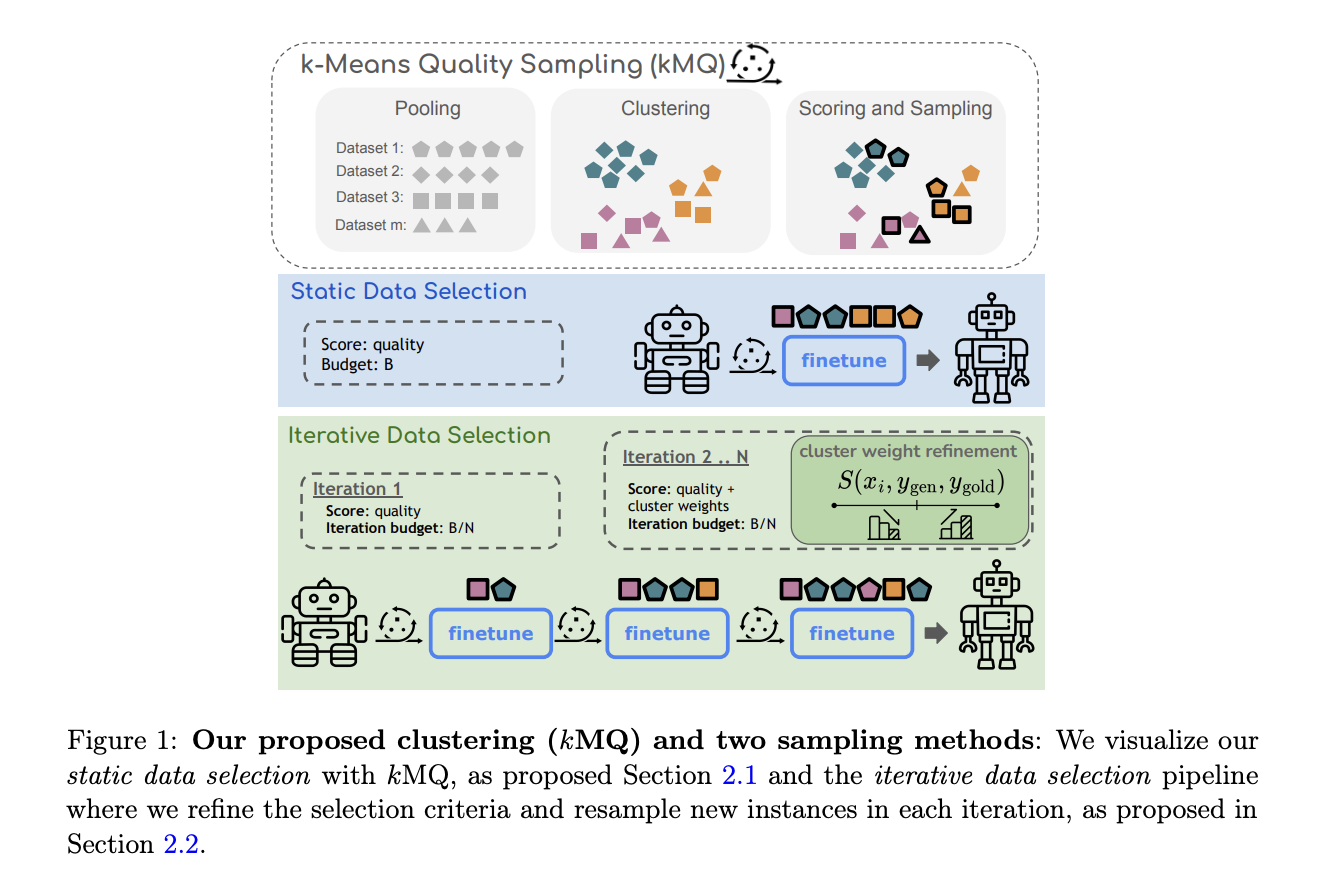
Исследователи из Университета Норт-Вестерн, Стэнфордского университета, исследовательского центра Google и Cohere For AI представили инновационный метод итеративного усовершенствования для преодоления этих препятствий. Их подход подчеркивает выбор данных, ориентированный на разнообразие с использованием кластеризации k-means. Этот метод гарантирует, что выбранное подмножество данных более точно представляет полный набор данных. Исследователи предлагают процесс итеративного усовершенствования, вдохновленный техниками активного обучения, который позволяет модели повторно выбирать примеры из кластеров во время обучения. Этот итеративный подход обеспечивает постепенное отфильтровывание кластеров, содержащих низкокачественные или выбросовые данные, с более акцентированным вниманием на разнообразных и представительных точках данных. Метод стремится к балансу между качеством и разнообразием, гарантируя, что модель не станет предвзятой к определенным категориям данных.
Введенный метод качества k-means (kMQ) выбирает и кластеризует точки данных в группы на основе сходства. Затем алгоритм выбирает данные из каждого кластера, чтобы сформировать подмножество обучающих данных. Каждому кластеру присваивается вес выборки, пропорциональный его размеру, корректируемый во время обучения в зависимости от того, насколько хорошо модель учится из каждого кластера. По сути, кластеры с высококачественными данными получают приоритет, в то время как тем с более низким качеством уделяется меньше внимания в последующих итерациях. Итеративный процесс позволяет модели улучшать свои знания по мере продвижения обучения, внося корректировки по мере необходимости. Этот метод противопоставляется традиционным фиксированным методам выборки, которые не учитывают поведение обучения модели во время обучения.
Эффективность этого метода была тщательно протестирована на нескольких задачах, включая вопросно-ответное взаимодействие, рассуждения, математику и генерацию кода. Исследовательская группа оценила свою модель на нескольких эталонных наборах данных, таких как MMLU (вопросы и ответы в академической области), GSM8k (математика начальной школы) и HumanEval (генерация кода). Результаты были значительными: метод выборки kMQ привел к улучшению производительности на 7% по сравнению с случайным выбором данных и на 3,8% по сравнению с передовыми методами, такими как Deita и QDIT. На задачах, таких как HellaSwag, тестирующих здравый смысл, модель достигла точности 83,3%, в то время как в GSM8k модель увеличила точность с 14,5% до 18,4% с использованием итеративного процесса kMQ. Это продемонстрировало эффективность выборки, ориентированной на разнообразие, в улучшении обобщения модели по различным задачам.
Метод исследователей превзошел предыдущие методы эффективности с помощью этих существенных приростов производительности. В отличие от более сложных процессов, которые полагаются на большие языковые модели для оценки и фильтрации точек данных, kMQ достигает конкурентоспособных результатов без затратных вычислительных ресурсов. Используя простой алгоритм кластеризации и итеративное усовершенствование, процесс масштабируем и доступен, что делает его подходящим для различных моделей и наборов данных. Этот метод особенно полезен для исследователей, работающих с ограниченными ресурсами, которые все еще стремятся достичь высокой производительности при обучении LLM.
В заключение, эти исследования решают одну из самых значительных проблем при обучении больших языковых моделей: выбор высококачественного, разнообразного подмножества данных, максимизирующего производительность по всем задачам. Путем внедрения кластеризации k-means и итеративного усовершенствования исследователи разработали эффективный метод, который балансирует разнообразие и качество при выборе данных. Их подход приводит к улучшению производительности до 7% и гарантирует, что модели могут обобщать по широкому спектру задач.