Оптимизация трансформера: объяснение на основе гессиана превосходства Adam над SGD
Практические решения и ценность
Большие языковые модели (LLM) на основе архитектур Transformer революционизировали разработку ИИ. Однако сложность процесса их обучения остается плохо понятной. Одной из ключевых проблем в этой области является несогласованность производительности оптимизатора. В то время как оптимизатор Adam стал стандартом для обучения трансформеров, стохастический градиентный спуск с импульсом (SGD), который эффективен для сверточных нейронных сетей (CNN), показывает худшие результаты на моделях трансформера. Разрыв в производительности представляет собой вызов для исследователей. Решение этой загадки может улучшить теоретическое понимание обучения трансформера и нейронных сетей, что потенциально приведет к более эффективным методам обучения.
Существующие исследования включают несколько гипотез, объясняющих плохую производительность SGD на трансформерах по сравнению с Adam. Одна из теорий предполагает, что SGD испытывает трудности из-за тяжелохвостого стохастического шума в языковых задачах. Усилия по пониманию эффективности Adam привели к анализу сходимости для различных адаптивных методов градиента. Недавние исследования исследовали анализ спектра Гессе для MLP и CNN, выявив характерные «основные» и «выбросные» шаблоны. Сложности обучения трансформера связаны с различными явлениями, включая расхождение логитов, дегенерацию ранга в слоях внимания, рост нормы параметров, чрезмерную зависимость от остаточных ветвей и негативное влияние слойной нормализации.
Исследователи из Китайского университета Гонконга, Шэньчжэнь, Китай и Шэньчжэньского института исследований больших данных объяснили разрыв в производительности между SGD и Adam при обучении трансформеров. Их подход сосредотачивается на анализе спектра Гессе этих моделей и концепции «блочной гетерогенности», которая относится к значительному разнообразию спектров Гессе в различных блоках параметров в трансформерах. Более того, предполагается, что эта гетерогенность является ключевым фактором в неэффективности SGD. Экспериментальные результаты на различных архитектурах нейронных сетей и квадратичных задачах показывают, что производительность SGD сравнима с производительностью Adam в задачах без блочной гетерогенности, но ухудшается при наличии гетерогенности.
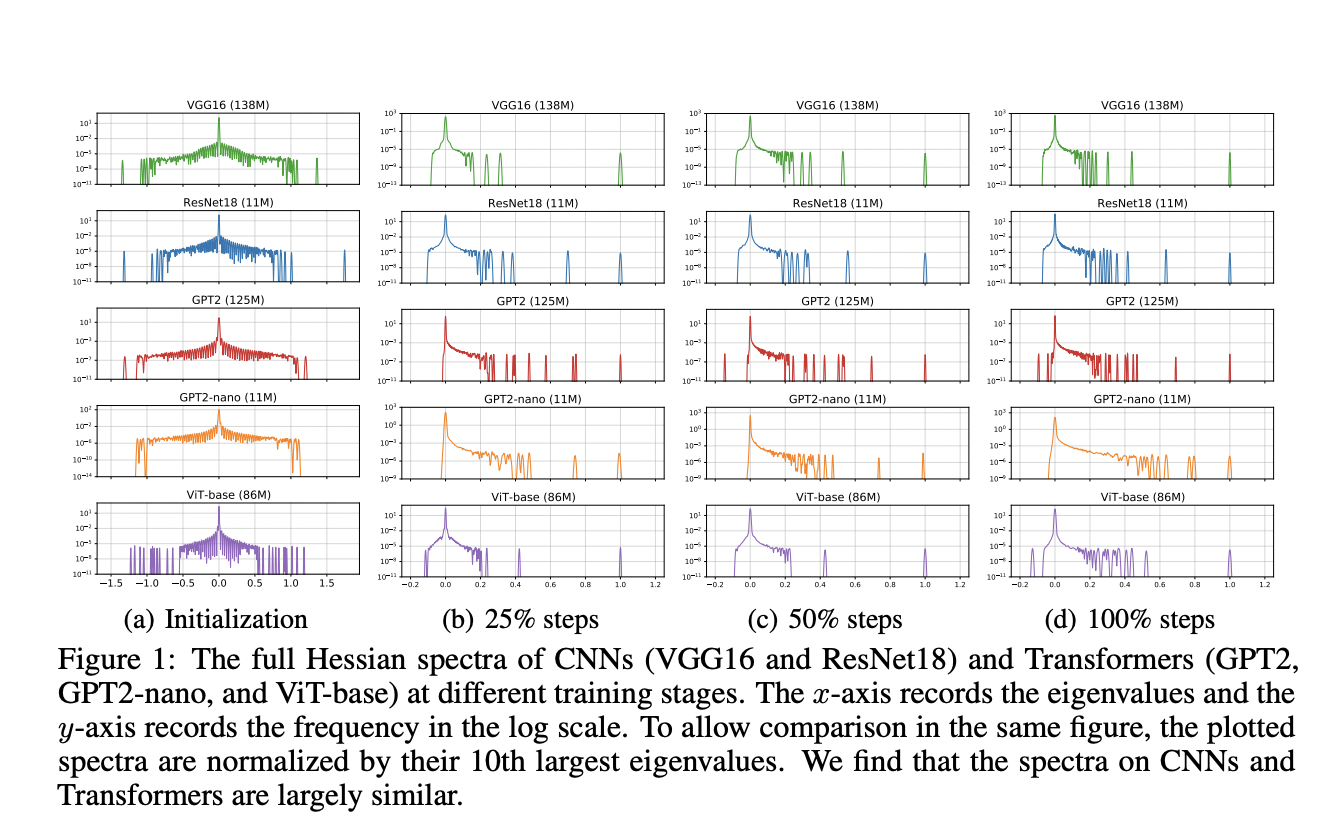
Предложенный метод использует метод стохастической квадратуры Ланцоша (SLQ) для приближения спектра Гессе крупномасштабных нейронных сетей, которые иначе слишком сложно вычислить и хранить. SLQ аппроксимирует гистограммы собственных значений, используя плавные кривые, и эта техника применяется для анализа различных моделей, включая CNN (ResNet18 и VGG16) и трансформеры (GPT2, ViT-base, BERT и GPT2-nano) для различных задач и модальностей. Для каждой модели оцениваются полный спектр Гессе и блочный спектр Гессе. Блоки параметров разделяются в соответствии с параметрами по умолчанию в реализации PyTorch, такими как слой встраивания, запрос, ключ и значение в слоях внимания.
Результаты показывают разницу в спектрах Гессе между моделями трансформеров и CNN. В трансформерах, таких как BERT, спектры Гессе демонстрируют значительные отклонения в различных блоках параметров, таких как встраивание, слои внимания и MLP. Это явление, называемое «блочной гетерогенностью», постоянно наблюдается во всех исследуемых моделях трансформера. С другой стороны, CNN, такие как VGG16, показывают «блочную однородность» с похожими спектрами Гессе в сверточных слоях. Эти различия количественно оцениваются с помощью расстояния Йенсена-Шеннона между плотностями собственных значений пар блоков. Эта блочная гетерогенность в трансформерах сильно коррелирует с разрывом в производительности между оптимизаторами SGD и Adam.
В данной статье исследователи исследовали основные причины неэффективности SGD по сравнению с Adam при обучении моделей трансформера. Введено понятие «блочной гетерогенности» в спектре Гессе, и установлена тесная связь между этим явлением и разрывом в производительности между Adam и SGD. Исследование предоставляет убедительные доказательства того, что «блочная гетерогенность», присутствующая в трансформерах, но не в CNN, значительно влияет на производительность оптимизатора. Более того, производительность SGD не хороша в присутствии «блочной гетерогенности», в то время как Adam остается эффективным. Эта работа предлагает ключевые идеи в оптимизации динамики нейронных сетей и прокладывает путь для более эффективных алгоритмов обучения для трансформеров и гетерогенных моделей.

























