Маскирование MaskLLM для оптимизации LLM
Практические решения и ценность
Большие размеры параметров LLM часто приводят к неэффективности из-за высоких требований к памяти и вычислениям. Одно из практических решений — полупространственное обрезание, особенно схема разреженности N: M, которая повышает эффективность, сохраняя N ненулевых значений среди M параметров. Этот подход сталкивается с вызовами из-за огромного пространства параметров в LLM. Методы, такие как SparseGPT и Wanda, используют небольшие наборы калибровки и критерии важности для выбора избыточных параметров. Однако эти методы ограничены в области применения, что затрудняет обобщение и вводит ошибки в представление качества модели в различных областях.
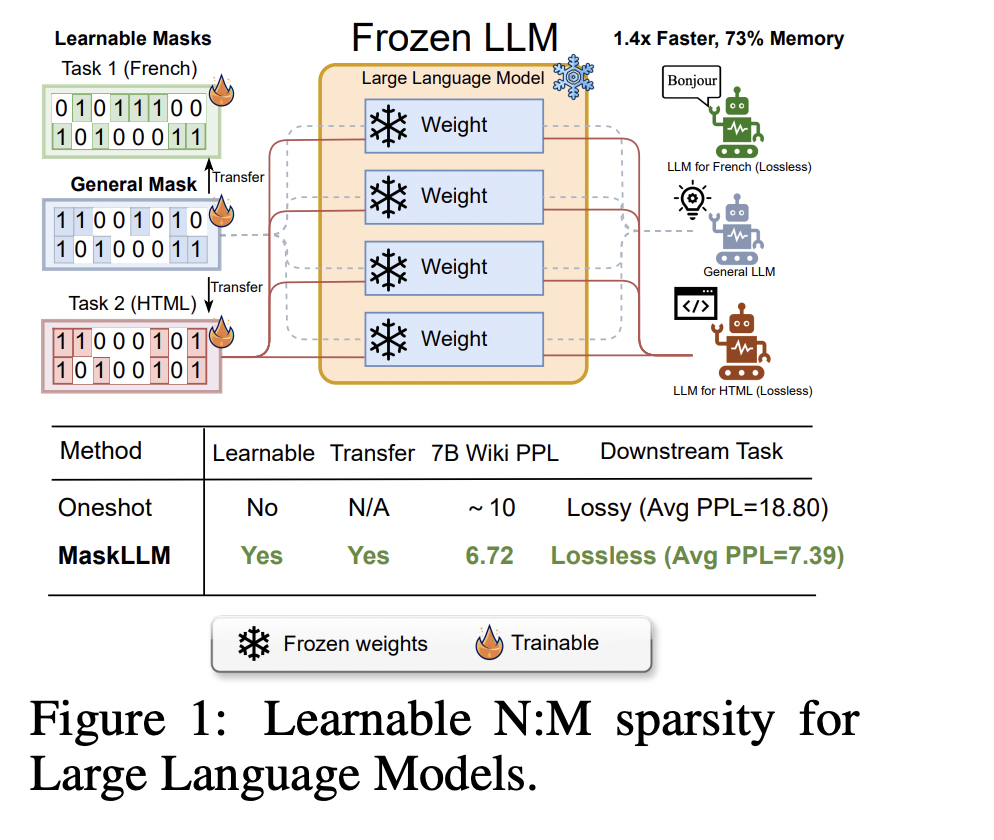
Исследователи из NVIDIA и Национального университета Сингапура представили метод MaskLLM, который применяет обучаемое обрезание схемы N: M к LLM, снижая вычислительные расходы во время вывода. В отличие от традиционных методов, MaskLLM использует выборку Gumbel Softmax для моделирования разреженности как обучаемого распределения, обеспечивая эффективное обучение от начала и до конца на больших наборах данных. Этот подход повышает точность и переносимость маски, позволяя применять обученные схемы разреженности в различных задачах или областях. Эксперименты на моделях, таких как LLaMA-2 и GPT-3, показывают значительные улучшения производительности, при этом MaskLLM достигает перплексии 6,72 по сравнению с 10,42 у SparseGPT.
Методы обрезки эффективны при сжатии LLM путем удаления избыточных параметров. Эти методы могут быть классифицированы на структурированное, неструктурированное и полуструктурированное обрезание. Структурированное обрезание удаляет подструктуры, такие как блоки внимания, в то время как неструктурированное обрезание обнуляет отдельные параметры, обеспечивая большую гибкость, но меньшую эффективность ускорения. Полуструктурированное обрезание, такое как схема разреженности N: M, достигает баланса, сочетая структурированные схемы с мелкозернистой разреженностью для повышения эффективности и гибкости. Недавно обучаемые методы разреженности привлекли внимание, особенно в моделях зрения, и данная работа является первоначальной в области применения обучаемых масок N: M в замороженных LLM, решая проблему масштабных параметров.
Фреймворк MaskLLM вводит схему разреженности N: M для оптимизации LLM путем выбора двоичных масок для блоков параметров, обеспечивая эффективное обрезание без значительного ухудшения производительности модели. Сосредотачиваясь на схеме 2:4 разреженности, он выбирает маски, в которых два из четырех значений остаются ненулевыми. Проблема выбора недифференцируемой маски решается через Gumbel Softmax, обеспечивая дифференцируемую выборку и оптимизацию маски с помощью градиентного спуска. MaskLLM изучает маски на основе данных большого масштаба, передавая их на последующие задачи. Регуляризация разреженных весов поддерживает качество после обрезки, а предварительные маски улучшают процесс обучения, обеспечивая эффективную и эффективную компрессию модели.
Исследователи оценили MaskLLM на нескольких LLM (LLaMA-2, Nemotron-4, GPT-3 многоязычный) с числом параметров от 843 млн до 15 млрд. MaskLLM изучает маски разреженности 2:4 в рамках обучения от начала и до конца, превосходя базовые методы, такие как SparseGPT и Wanda, по точности и перплексии. Метод улучшает качество маски с использованием больших наборов данных и проявляет устойчивость в условиях ограниченных ресурсов. Обучение передачи с использованием предварительно рассчитанных масок ускоряет обучение, сохраняя при этом большие оставшиеся веса, что улучшает производительность последующих задач. Стохастическая исследовательская эксплорация MaskLLM обеспечивает обнаружение масок высокого качества, превосходя результаты SparseGPT в перплексии после обучения с 1280 примерами.
MaskLLM представляет обучаемый метод обрезки для применения разреженности N: M в LLM с целью снижения вычислительных затрат во время вывода. Вместо использования заранее определенного критерия важности он моделирует схемы разреженности N: M через выборку Gumbel Softmax, обеспечивая обучение от начала и до конца на больших наборах данных. MaskLLM предлагает обучение масок высокого качества и переносимость между областями. Протестированный на LLaMA-2, Nemotron-4 и GPT-3, с размерами от 843 млн до 15 млрд параметров, MaskLLM превзошел современные методы по перплексии и эффективности. Его маски могут быть настроены для без потерь производительности последующих задач.

























