Применение GemFilter для Ускорения Вывода LLM и Снижения Потребления Памяти
Описание метода GemFilter
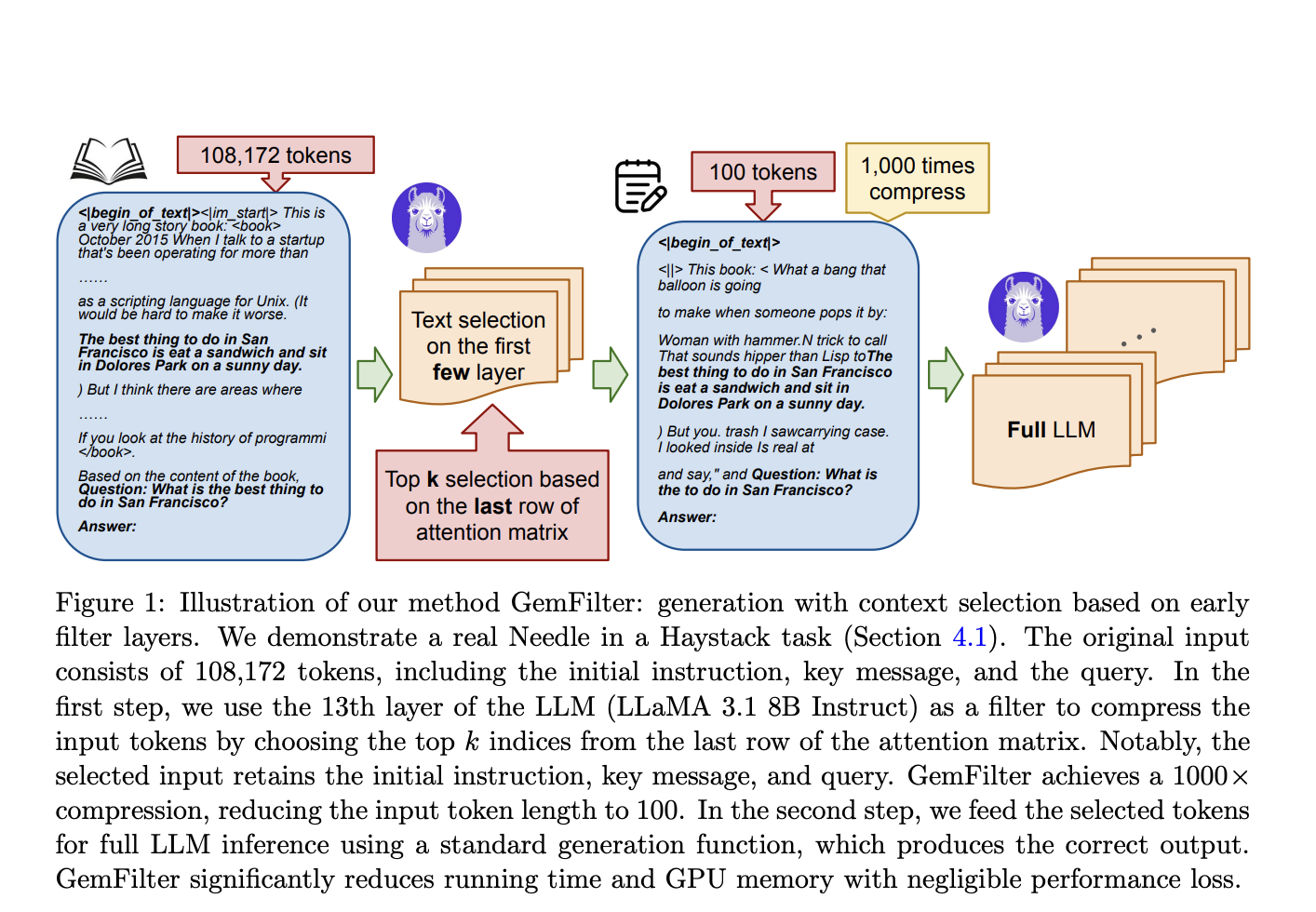
Метод GemFilter представляет собой инновационный подход к оптимизации вывода LLM для длинных контекстов, решая проблемы эффективности в скорости и использовании памяти. GemFilter использует ранние слои LLM для выявления ключевой информации и сжатия входных токенов, что позволяет значительно ускорить обработку и снизить потребление памяти.
Преимущества GemFilter
GemFilter демонстрирует впечатляющие результаты на различных бенчмарках, превосходя стандартное внимание и другие методы. Он обеспечивает сравнимую производительность при сжатии входных контекстов, что делает его мощным инструментом для оптимизации работы LLM с длинными контекстами.
Эффективность и Ресурсосбережение
По результатам экспериментов, GemFilter обеспечивает ускорение в 2,4 раза и снижение использования памяти GPU на 30% и 70% по сравнению с другими методами. Его трехэтапный подход к обработке контекста позволяет существенно экономить ресурсы, делая его выдающимся решением для работы с длинными входными данными.

























