Значение Reinforcement Learning with Execution Feedback (RLEF) в генерации кода
Практические решения и преимущества:
Большие языковые модели (LLMs) генерируют код с помощью обработки естественного языка. Применение генерации кода в сложных задачах, таких как разработка и тестирование программного обеспечения, становится все более популярным. Важна тщательная согласованность с вводом для получения умного и безошибочного результата, но разработчики определили это как вычислительно сложное и затратное по времени. Поэтому создание фреймворка для алгоритма, который постоянно совершенствуется, чтобы предоставлять обратную связь в реальном времени в виде сообщений об ошибках или негативных оценок, стало ключевым в решении этой проблемы.
Традиционно LLM обучались на алгоритмах обучения с учителем с использованием больших размеченных наборов данных. Они жесткие и имеют проблемы с обобщением, что затрудняет адаптацию LLM к среде пользователя. При этом алгоритм должен генерировать много образцов, что увеличивает вычислительные затраты. Для решения этой проблемы был предложен цикл обратной связи выполнения, благодаря которому модели учились согласовывать свои результаты с требованиями ввода, предоставляя обратную связь итеративно в данной среде. Этот механизм также сократил количество сгенерированных образцов. Однако зависимость от среды выполнения была недостатком.
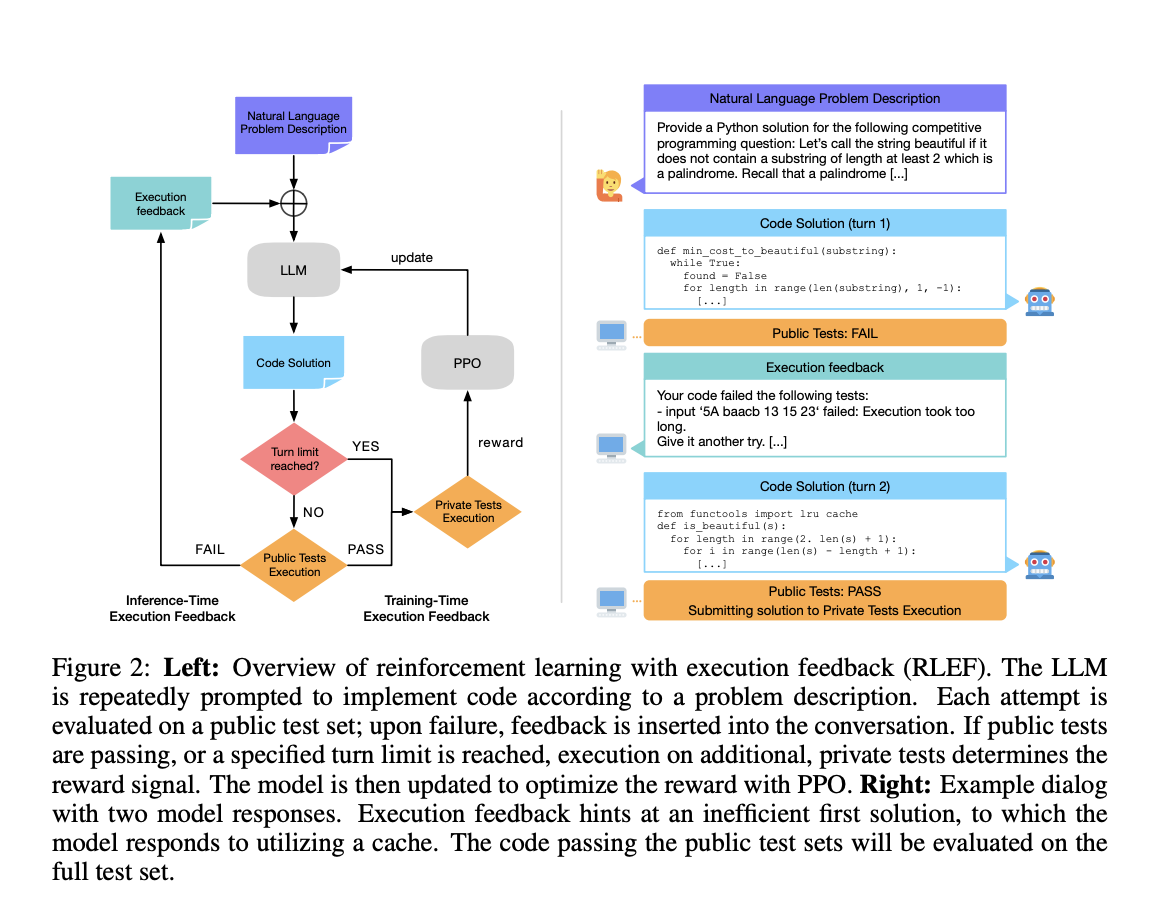
В данной статье команда исследователей Meta AI представляет фреймворк обучения с подкреплением, который использует кодовое дополнение цикла обратной связи выполнения. LLM генерирует код на основе инструкций пользователя, оценивает некоторые общедоступные тестовые случаи и предоставляет обратную связь. Этот процесс создает итеративный цикл, и алгоритм учится максимизировать вознаграждение. Инновацией фреймворка обучения с подкреплением было то, что цикл обратной связи был принужден взаимодействовать с различными средами.
В процессе обучения моделей в RLEF итеративное уточнение кода продолжается до тех пор, пока не будет достигнут конечный пункт: все общедоступные тестовые случаи успешно пройдены или проведен заранее определенный предел итераций. Для проверки также выполняется оценка на частных тестовых случаях, что помогает предотвратить переобучение. Возможно описать этот процесс в рамках процесса принятия решения Маркова (MDP). Система вознаграждения четко определена, и положительные баллы за вознаграждение присуждаются только при успешном прохождении каждого тестового случая. Во всех остальных случаях всегда есть штраф. Перед получением окончательного результата поведение LLM дополнительно настраивается с использованием метода оптимизации ближней политики (PPO).
Источником кода для этого эксперимента служило сравнительный анализ с бенчмарком CodeContests. Предшествующие результаты показали, что благодаря обучению в RLEF производительность моделей улучшилась в случае ограничения до нескольких ситуаций с образцами, но не в случае использования больших выборок. На старых моделях показатель успешного решения возрастает с 4,1 до 12,5 на проверочном наборе и с 3,2 до 12,1 на тестовом наборе. Перед обучением в RLEF обратная связь между ходами не улучшала базовые модели, такие как GPT-4 или более крупная 70B Llama 3.1. После обучения в RLEF модели намного лучше улучшают более крупную 70B Llama 3.1 в многоповоротных сценариях благодаря обратной связи на этапе выполнения. Также было отмечено, что модели, обученные с RLEF, делают более разнообразные и точные изменения кода между ответами по сравнению с моделями без RLEF, которые часто возвращают ошибочные решения снова и снова, несмотря на полученное руководство.
В заключение, обучение с подкреплением с обратной связью выполнения (RLEF) является прорывом для больших языковых моделей (LLMs) в генерации кода. Таким образом, итеративный цикл обратной связи также гибок для различных настроек, улучшает RLEF и значительно повышает способность моделей корректировать результат на основе текущей производительности. Исследования показывают увеличение эффективности модели в обработке многоповоротных разговоров, сокращение вычислительного времени и уровня ошибок. RLEF представляет собой эффективный подход к преодолению проблем обучения с учителем и помогает развивать эффективное и адаптивное программирование для разработки программного обеспечения.

























