Решение проблемы вычисления схожести графов с помощью SEGMN
В современных приложениях вычисление схожести графов (GSC) имеет важное значение для таких задач, как обнаружение кода, определение схожести молекулярных графов и сопоставление изображений. GSC основывается на обучении схожести графов. Наиболее распространенные методы измерения схожести графов — это расстояние редактирования графов (GED) и максимальный общий подграф (MCS).
Проблемы существующих методов
Существующие методы вычисления схожести графов имеют два основных недостатка:
- Ограниченность представления: Большинство методов используют простые представления узлов, не учитывая важность рёбер в сравнении структур.
- Недостаточность сопоставления: Современные методы не полностью используют информацию о рёбрах, что приводит к неправильным оценкам схожести.
Решение от Nanjing University
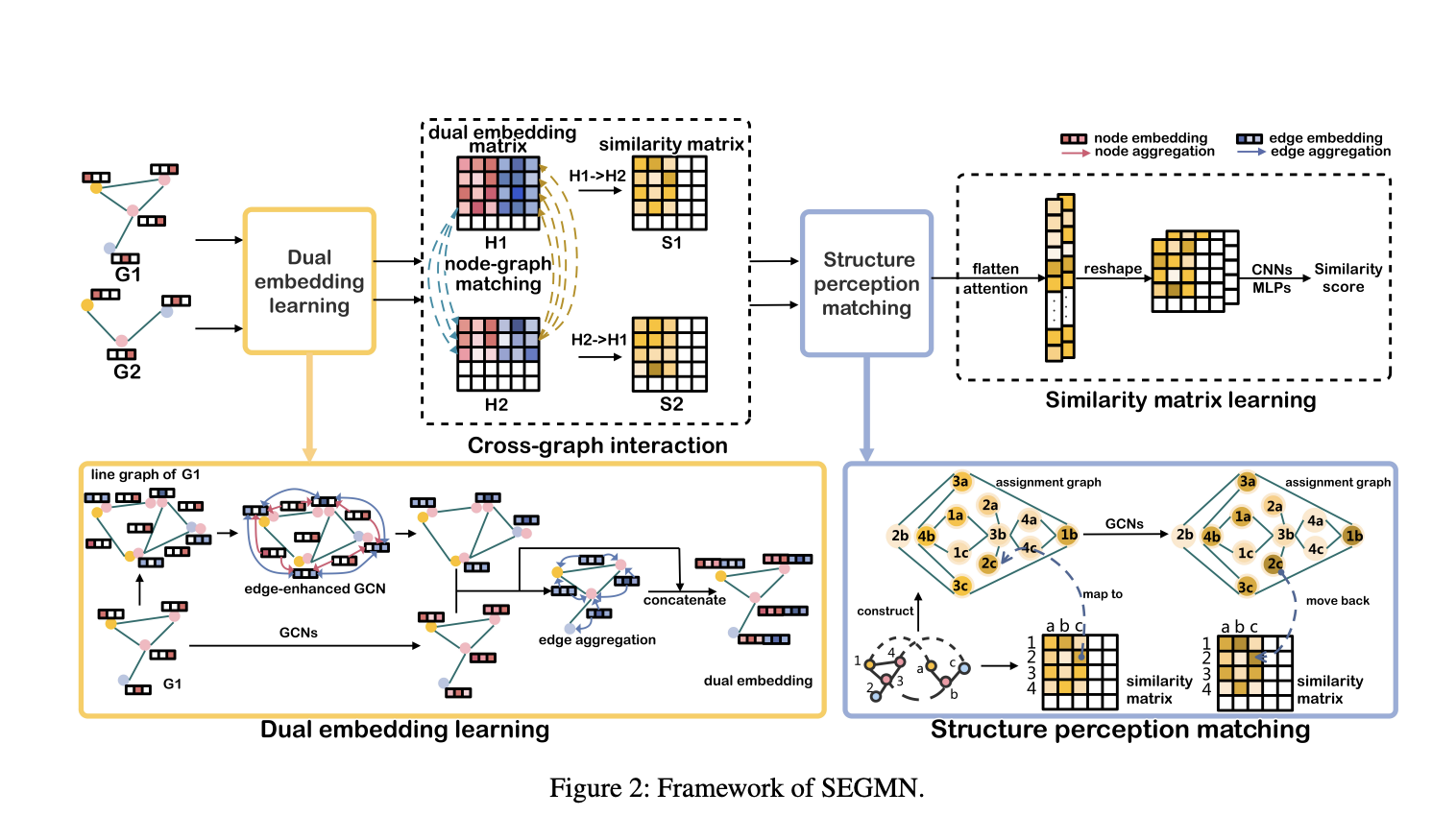
Чтобы преодолеть эти недостатки, исследователи предложили структурированную улучшенную сеть сопоставления графов (SEGMN). Эта структура включает в себя четыре модуля:
- Двухуровневое обучение представлений
- Взаимодействие между графами
- Сопоставление на основе восприятия структуры
- Обучение матрицы схожести
Преимущества SEGMN
Модуль двухуровневого обучения проходит три этапа, включая использование графа с улучшением рёбер для создания представлений. Затем происходит агрегирование рёбер для получения окончательного представления. Модуль сопоставления структуры улучшает оценки схожести, учитывая структурные отношения между узлами.
Исследования показали, что SEGMN превосходит другие модели в таких показателях, как среднеквадратичная ошибка (MSE) и точность при оценке.
Заключение
Предложенная структура обеспечивает точное вычисление схожести графов и представляет собой важный шаг в области анализа графов. Она может служить основой для будущих исследований и внедрения решений на основе ИИ в различных сферах.

























