Введение в SuffixDecoding
Большие языковые модели (LLM) стали основой современных приложений. Однако быстрый генерация токенов остается проблемой, замедляя работу приложений. Решение этой проблемы крайне важно для развития и внедрения приложений на базе LLM.
Проблемы существующих методов
Существующие методы декодирования имеют ограничения, такие как:
- Зависимость от размеров и качества черновой модели.
- Сложности с интеграцией черновых моделей на GPU.
Недавно предложенный метод SuffixDecoding решает эти проблемы, не требуя черновых моделей и дополнительных декодирующих голов.
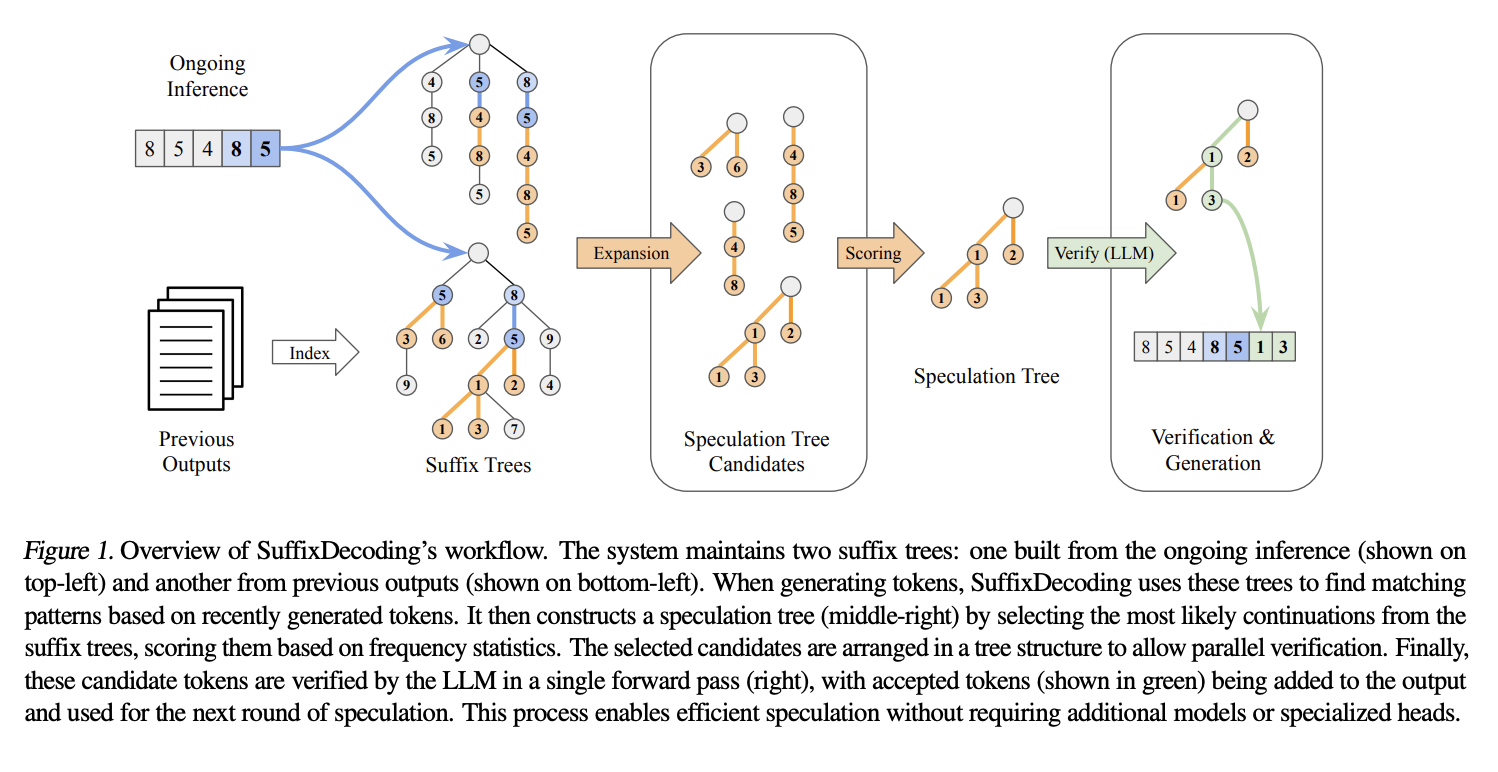
Как работает SuffixDecoding
SuffixDecoding использует эффективные суффиксные деревья, построенные на основе предыдущих выходов и текущего запроса. Процесс начинается с токенизации каждой пары запрос-ответ и построения суффиксного дерева.
Каждый узел дерева представляет токен, а путь от корня к узлу соответствует подсеквенции, которая была в обучающих данных. Это позволяет избежать сложностей и затрат GPU, связанных с использованием черновых моделей.
Преимущества SuffixDecoding
При каждом новом запросе SuffixDecoding строит отдельное суффиксное дерево. Это особенно важно для задач, где вывод LLM должен ссылаться на входные данные, таких как:
- Суммирование документов.
- Ответы на вопросы.
- Многоходовые беседы.
- Редактирование кода.
Суффиксное дерево позволяет эффективно отслеживать частоту последовательностей токенов, что ускоряет процесс сопоставления паттернов.
Экспериментальные результаты
Эксперименты показывают, что SuffixDecoding обеспечивает до 2.9 раз большую пропускную способность и в 3 раза меньшую задержку по сравнению с предыдущими методами. Это подтверждает его эффективность для работы с LLM в сложных сценариях.
Выводы
SuffixDecoding представляет собой модель, которая ускоряет вывод LLM, используя суффиксные деревья. Этот подход позволяет значительно повысить эффективность и расширяет возможности больших языковых моделей в реальных приложениях.
Как использовать ИИ в вашей компании
Чтобы ваша компания развивалась с помощью ИИ, следуйте этим шагам:
- Анализируйте, как ИИ может изменить вашу работу.
- Определите, где можно применять автоматизацию.
- Установите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Подберите подходящее решение из множества доступных ИИ.
- Внедряйте ИИ постепенно, начиная с малого проекта и анализируя результаты.
Получение помощи
Если вам нужны советы по внедрению ИИ, свяжитесь с нами. Мы готовы помочь вам с эффективными решениями для вашего бизнеса.

























