Преимущества H-DPO для выравнивания языковых моделей
Большие языковые модели (LLMs) показывают отличные результаты в различных приложениях, но их широкое применение сталкивается с серьезными проблемами. Основная проблема заключается в обучающих наборах данных, которые содержат разнообразный и потенциально вредный контент. Это создает необходимость согласования выходных данных LLM с конкретными требованиями пользователей и предотвращения злоупотреблений.
Проблемы и решения
Существующие методы, такие как обучение с подкреплением на основе человеческой обратной связи (RLHF), пытаются решить эти проблемы, однако они имеют ограничения из-за высоких вычислительных затрат и сложных моделей вознаграждения. Это требует более эффективных методов для настройки LLM, сохраняя их производительность и обеспечивая ответственное развитие ИИ.
Методы выравнивания
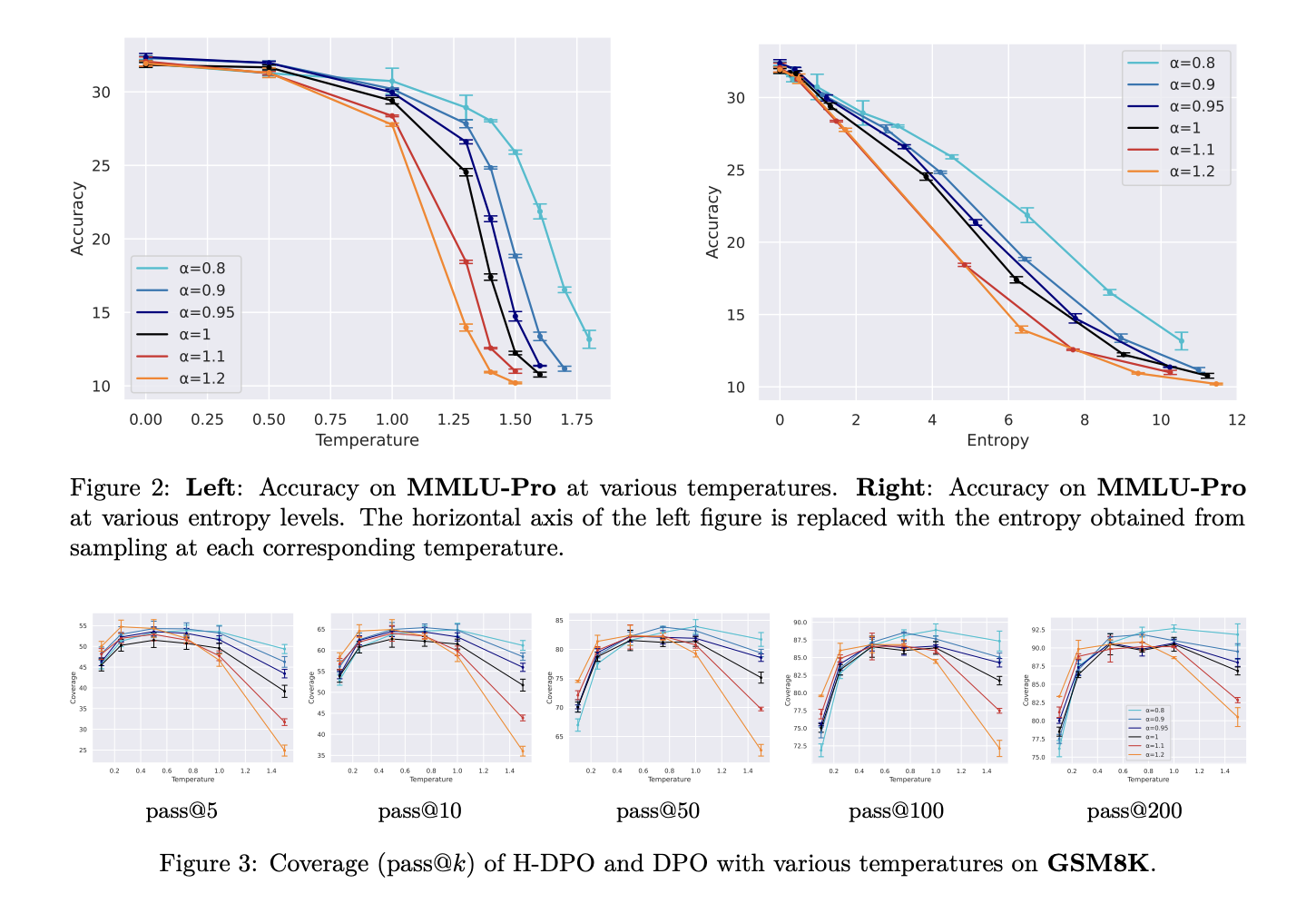
Различные методы выравнивания появились для решения задач настройки LLM с учетом человеческих предпочтений. H-DPO – это новая модификация традиционного DPO, которая решает ограничения поведения поиска режимов. Ключевое нововведение заключается в контроле энтропии распределения политики, что позволяет более эффективно захватывать целевые режимы распределения.
Преимущества H-DPO
Метод H-DPO демонстрирует значительные улучшения по сравнению со стандартным DPO в различных задачах, таких как:
- Математические задачи (GSM8K)
- Кодирование (HumanEval)
- Вопросы с выбором ответа (MMLU-Pro)
- Задачи по следованию инструкциям (IFEval)
Снижение значения α до 0.95 и 0.9 привело к улучшению производительности во всех задачах. Важным аспектом является контроль разнообразия ответов, что особенно актуально в задачах, требующих решения через множество сгенерированных образцов.
Простота внедрения
H-DPO предлагает простую, но эффективную модификацию стандартной DPO. Его инновационный механизм контроля энтропии через гиперпараметр α позволяет достичь лучшего поведения поиска режимов и более точного контроля над распределением выходных данных. Это делает H-DPO ценным вкладом в область выравнивания языковых моделей.
Как использовать ИИ в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, рассмотрите внедрение H-DPO. Проанализируйте, как ИИ может изменить вашу работу:
- Определите области для автоматизации.
- Установите ключевые показатели эффективности (KPI), которые хотите улучшить.
- Выберите подходящее ИИ-решение и внедряйте его постепенно.
Если вам нужны советы по внедрению ИИ, пишите нам.

























