Введение в INCLUDE: Новый стандарт оценки многоязычного понимания языка
Быстрое развитие технологий ИИ подчеркивает необходимость в больших языковых моделях (LLMs), которые могут эффективно работать в различных языковых и культурных контекстах. Главной проблемой является недостаток оценочных критериев для неанглийских языков, что ограничивает потенциал LLM в недостаточно обслуживаемых регионах.
Проблемы существующих оценочных методов
Большинство существующих оценочных фреймворков сосредоточены на английском языке, что создает препятствия для разработки справедливых технологий ИИ. Это также сдерживает практиков от обучения многоязычных моделей и увеличивает цифровой разрыв между различными языковыми сообществами. Технические проблемы, такие как ограниченное разнообразие наборов данных и методы сбора данных на основе перевода, только усугубляют ситуацию.
Прогресс в разработке оценочных стандартов
Ученые разработали множество оценочных стандартов, таких как GLUE и SuperGLUE, которые продвинули задачи понимания языка. Однако большинство из них в основном сосредоточены на английских данных, что создает значительные ограничения для многоязычного моделирования. Новые наборы данных, такие как Exams и Aya, пытаются охватить более широкие языковые области, но их объем ограничен.
Решение INCLUDE
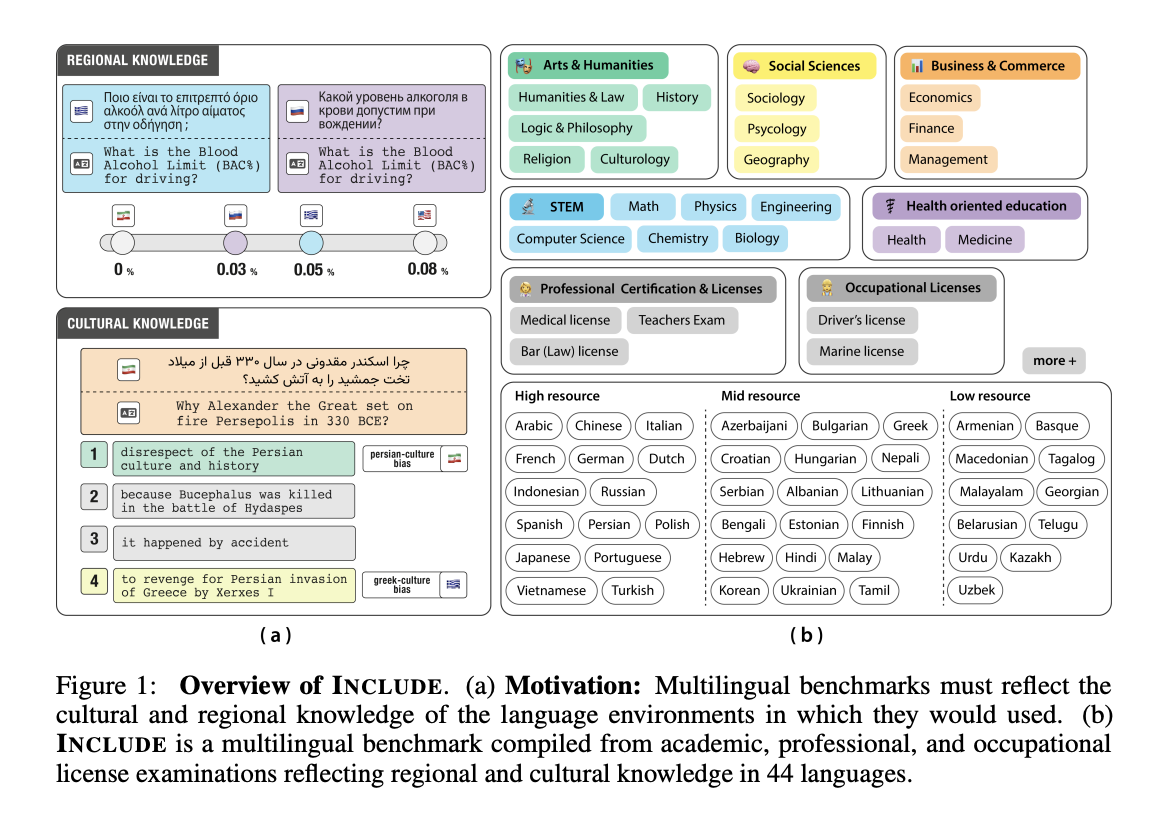
Исследователи из EPFL, Cohere For AI, ETH Zurich и Швейцарской ИИ Инициативы предложили новый многоязычный оценочный стандарт INCLUDE. Он заполняет критические пробелы в существующих оценочных методологиях, собирая ресурсы из местных источников на родном языке. Включает 197,243 вопроса с вариантами ответов из 1,926 экзаменов на 44 языках и 15 уникальных письмах, собранных из местных источников в 52 странах.
Методология аннотирования
Стандарт INCLUDE использует сложную методологию аннотирования для изучения факторов, влияющих на многоязычную производительность. Исследователи разработали подход к категоризации, который упрощает аннотирование за счет маркировки источников экзаменов. Этот метод позволяет лучше понять состав набора данных, управляя затратами на аннотирование.
Результаты и выводы
Оценка стандарта INCLUDE показала значительные различия в производительности многоязычных LLM. Модель GPT-4o продемонстрировала наилучшие результаты, достигнув точности около 77.1% во всех областях. Большие модели, такие как Aya-expanse-32B и Qwen2.5-14B, показали значительные улучшения в производительности по сравнению с меньшими моделями.
Заключение
Стандарт INCLUDE представляет собой шаг вперед в оценке многоязычных LLM. Он обеспечивает основу для оценки понимания региональных и культурных знаний в системах ИИ. Эта работа подчеркивает необходимость продолжения инноваций в создании более справедливых и культурно осведомленных технологий ИИ.
Как внедрить ИИ в вашу компанию
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ и оставалась в числе лидеров, следуйте этим шагам:
- Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации.
- Определите ключевые показатели эффективности (KPI). Решите, что вы хотите улучшить с помощью ИИ.
- Подберите подходящее решение. Существует много вариантов ИИ.
- Внедряйте ИИ постепенно. Начните с малого проекта, анализируйте результаты и KPI.
- Расширяйте автоматизацию на основе полученных данных и опыта.
Если вам нужны советы по внедрению ИИ, пишите нам. Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























