Введение
Модели большого языка (LLM) сегодня значительно продвигаются в области исследований и разработок. Однако высокие затраты делают их недоступными для многих компаний. Существует необходимость в снижении задержек операций, особенно в динамичных приложениях.
Проблемы с производительностью
KV-кэш используется для декодирования в LLM и хранит ключи и значения, что снижает сложность операций. Однако размер кэша растет, что превышает возможности графических процессоров (GPU) и увеличивает задержки.
Новая методология
Исследователи Университета Южной Калифорнии предложили эффективный метод LLM, который оптимизирует использование PCIe. Этот метод включает частичную рекомпиляцию KV-кэша и асинхронную передачу данных.
Как это работает:
- Передача сегментов: Вместо передачи всего кэша, передаются меньшие сегменты, что ускоряет процесс.
- Автоматизированный подход: Используется три модуля для минимизации задержек GPU.
Модули системы:
- Модуль профилирования: Сбор информации о системе.
- Модуль планирования: Определяет оптимальные точки разделения данных для максимизации производительности.
- Временной модуль: Координирует передачу данных между устройствами.
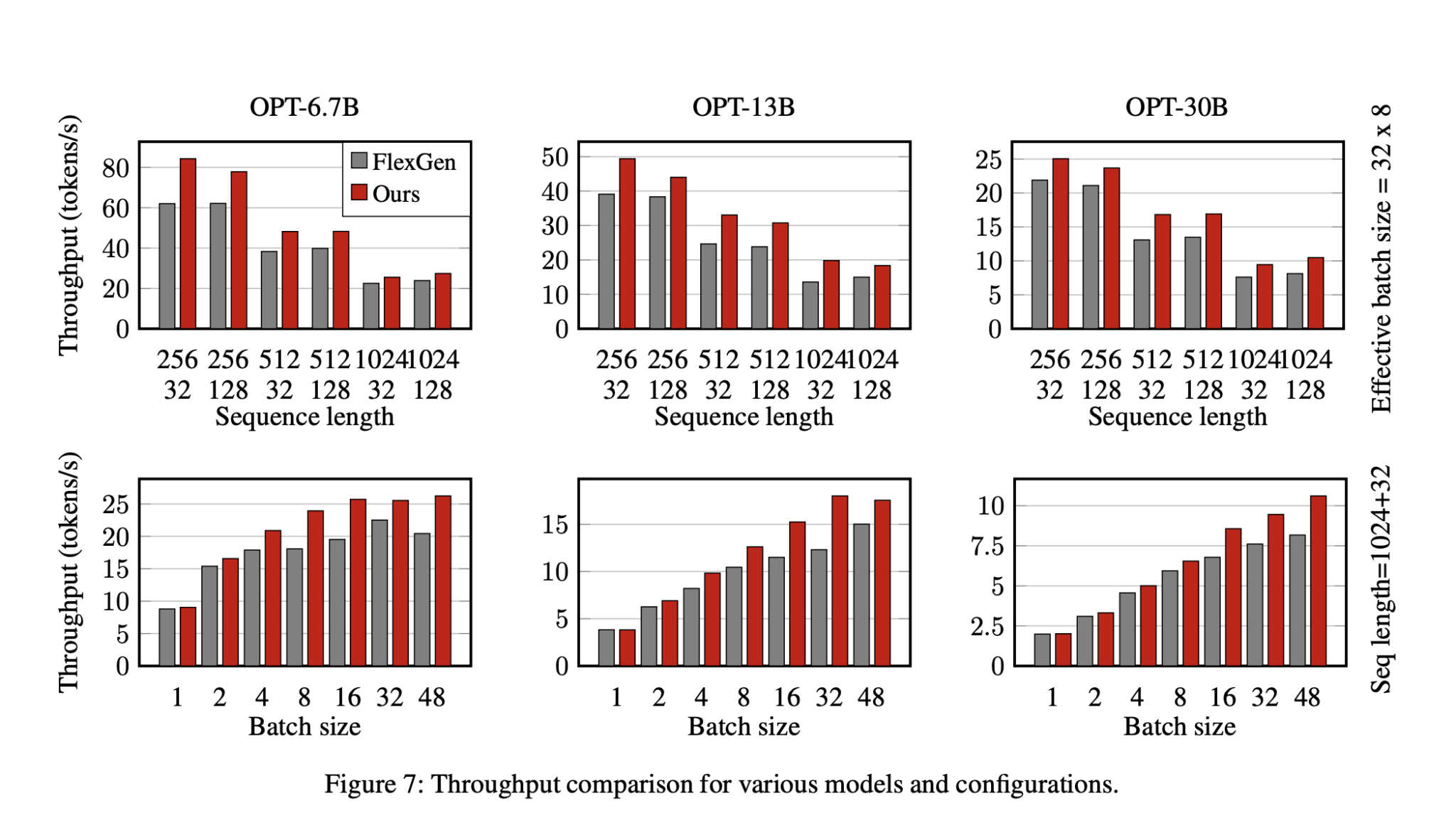
Результаты
Тестирование показало, что предложенный метод сокращает задержку на 35.8% и увеличивает производительность на 29% по сравнению с базовыми показателями.
Заключение
Метод CPU-GPU I/O-aware LLM эффективно снижает задержки и увеличивает производительность в инференсе LLM, что позволяет оптимизировать использование ресурсов.
Как использовать ИИ в вашей компании
- Анализируйте: Определите, как ИИ может изменить вашу работу.
- Ключевые показатели: Установите KPI, которые хотите улучшить.
- Подбор решений: Выбирайте подходящие ИИ-решения и внедряйте их постепенно.
Если вам нужны советы по внедрению ИИ, свяжитесь с нами. Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























