«`html
Применение обучения с подкреплением (RL)
Обучение с подкреплением сейчас используется почти во всех областях науки и технологий. Оно помогает оптимизировать процессы и системы. Однако у RL есть некоторые проблемы, такие как неэффективное использование образцов. Это означает, что RL нужно много испытаний, чтобы научиться простым задачам, которые человек осваивает быстро.
Решение: Meta-RL
Meta-RL решает эту проблему, давая агенту возможность использовать прошлый опыт. Агент запоминает предыдущие испытания, что помогает ему адаптироваться к новым условиям и использовать данные более эффективно. Meta-RL умнее стандартного RL, так как он может изучать сложные стратегии, ставя задачи, которые RL не может решить сам.
Проблемы Meta-RL
Существующие методы Meta-RL стремятся максимизировать общую награду, находя баланс между исследованием и использованием. Однако даже современные методы могут застревать на локальных максимумах, особенно когда агент должен жертвовать немедленной наградой ради потенциально большей награды в будущем.
Новое решение: First-Explore
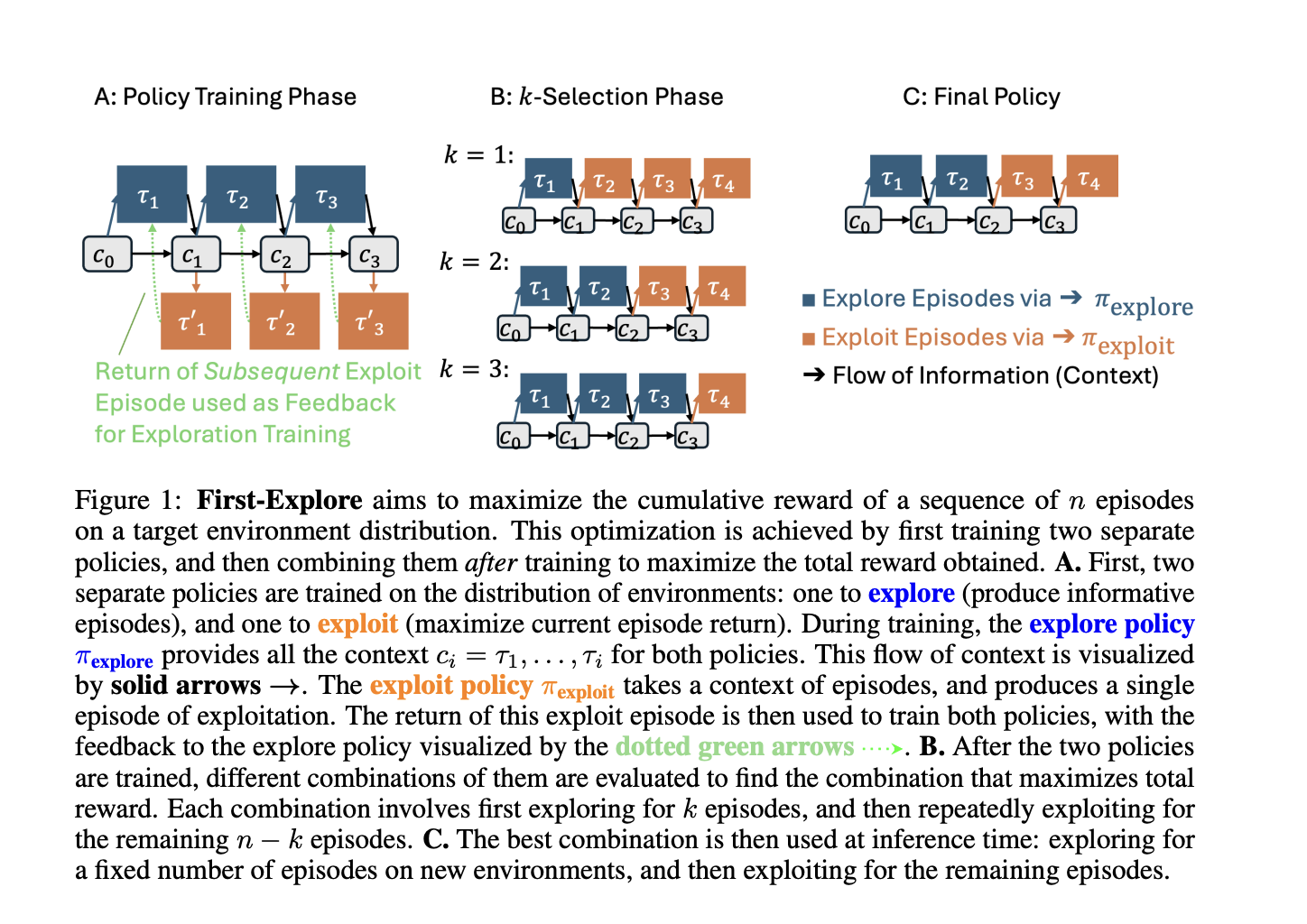
Исследователи Университета Британской Колумбии разработали метод «First-Explore, Then Exploit», который отделяет исследование от использования, обучая два разных подхода. Сначала используется политика исследования, которая подсказывает политике использования, как максимизировать награды. Эти две политики обучаются независимо, но комбинируются после обучения для максимизации общей награды.
Политика исследования генерирует эпизоды, которые помогают политике использования давать более высокие награды. Реализация First-Explore основана на архитектуре трансформера, аналогичной GPT-2.
Эксперименты и результаты
В ходе экспериментов First-Explore показал в два раза больше наград по сравнению с традиционными подходами Meta-RL в одной из задач. В других задачах результаты были даже лучше: в 10 раз и в 6 раз соответственно, что доказывает высокую эффективность First-Explore.
Заключение
First-Explore представляет собой эффективное решение проблемы немедленных наград, которое беспокоит традиционный Meta-RL. Тем не менее, он сталкивается с определенными сложностями, которые требуют дальнейших исследований, такими как отсутствие долгосрочного планирования и игнорирование негативных наград.
Как искусственный интеллект может помочь вашему бизнесу
Если вы хотите развивать свою компанию с помощью ИИ, важно правильно применять новые методы.
- Анализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые вы хотите улучшить с помощью ИИ.
- Подберите подходящее решение, учитывая многообразие доступных ИИ.
- Внедряйте ИИ постепенно, начиная с небольших проектов и анализируя результаты.
- На основе полученных данных расширяйте автоматизацию процессов.
При необходимости отремонтируйте свои процессы с помощью решений от Flycode.ru и получите больше информации о возможностях ИИ для вашей компании.
«`

























