Пре-тренировка языковых моделей (LMs)
Пре-тренировка языковых моделей играет важную роль в их способности понимать и генерировать текст. Однако существует проблема эффективного использования разных источников данных, таких как Википедия, блоги и социальные сети. Модели обычно рассматривают все входные данные одинаково, не учитывая контекст.
Основные проблемы:
- Недостаток контекстуальных сигналов: Игнорирование метаданных, таких как URL, мешает моделям понимать намерения текста.
- Неэффективность в специализированных задачах: Однообразное обращение к разным данным снижает эффективность выполнения задач, требующих особых знаний.
Решение от Принстонского университета
Исследователи из Принстонского университета разработали метод Metadata Conditioning then Cooldown (MeCo), чтобы решить проблемы стандартной пре-тренировки. MeCo использует доступные метаданные, добавляя их к тексту на этапе пре-тренировки.
Этапы работы MeCo:
- Metadata Conditioning (Первый 90%): Метаданные, такие как “URL: wikipedia.org”, добавляются к документу, что помогает модели усваивать связь между метаданными и содержимым.
- Cooldown Phase (Последние 10%): Обучение продолжается без метаданных, чтобы гарантировать обобщение модели на сценарии без метаданных.
Преимущества MeCo
- Улучшенная эффективность данных: MeCo требует меньше данных для обучения, достигая тех же результатов с 33% меньшими затратами.
- Улучшенная адаптивность модели: Учет метаданных помогает моделям обеспечивать желаемые характеристики, такие как повышенная точность.
- Минимальные затраты: MeCo почти не добавляет сложности или затрат в процесс обучения.
Результаты и выводы
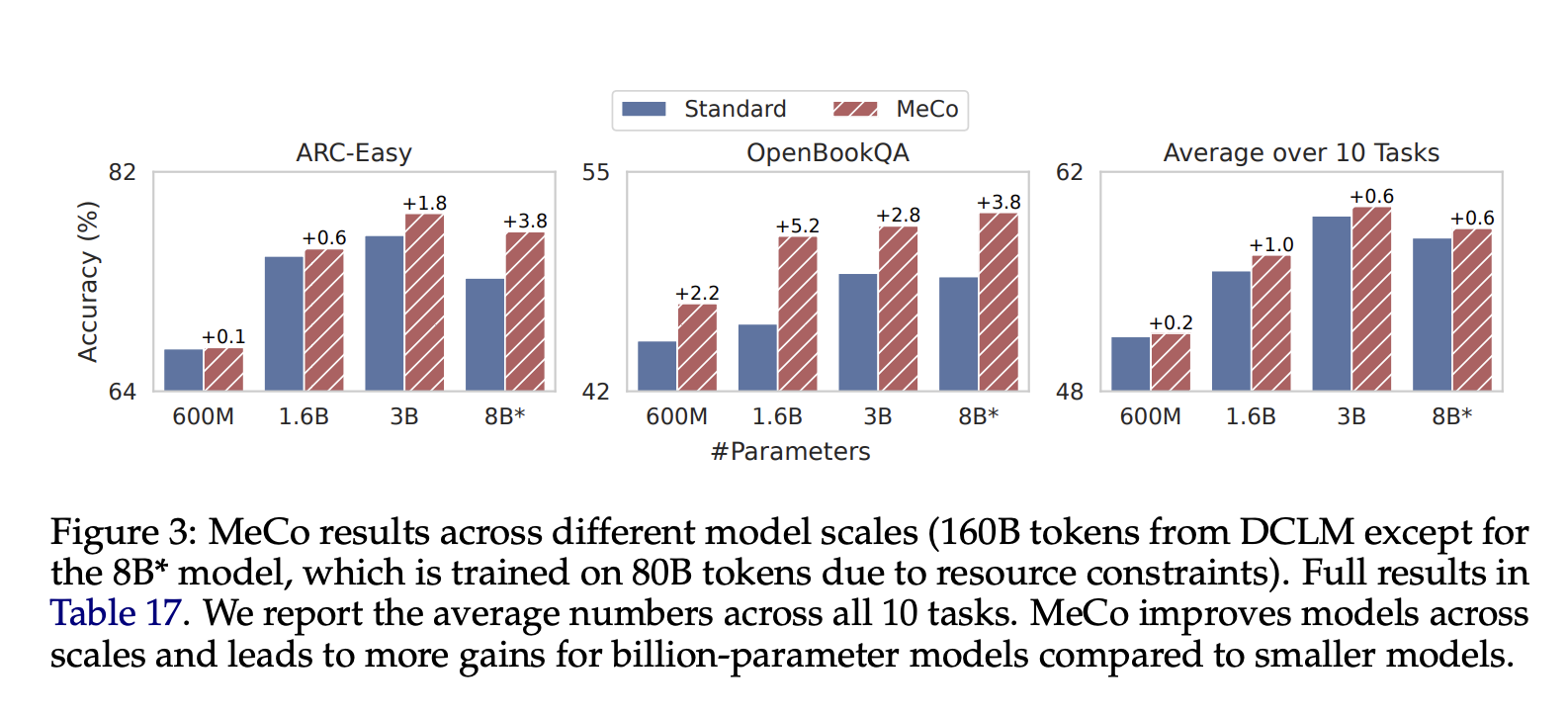
MeCo продемонстрировала улучшение производительности по сравнению со стандартной пре-тренировкой в различных задачах. Например, использовав модели от 600M до 8B параметров, исследования показали:
- В среднем, MeCo улучшила производительность на 1.0% в 10 задачах для модели с 1.6B параметров.
- Снижение токсичности выходных данных при использовании специфических метаданных.
Заключение
Метод MeCo является практичным и эффективным способом оптимизации пре-тренировки языковых моделей. Используя метаданные, MeCo решает проблемы стандартной пре-тренировки, снижая требования к данным и улучшая производительность.
Как внедрить ИИ в вашу компанию?
Если вы хотите развивать вашу компанию с помощью искусственного интеллекта (ИИ), следуйте этим шагам:
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите, где можно применить автоматизацию для пользы клиентов.
- Установите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Начните с малого проекта, анализируйте результаты и расширяйте автоматизацию на основе полученных данных.
Получите советы по внедрению ИИ
Если нужны советы, пишите нам. Попробуйте нашего ИИ ассистента в продажах, который поможет отвечать на вопросы клиентов и снижать нагрузку на команду.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























