Модели языка и их развитие
Модели языка (LMs) значительно продвинулись благодаря увеличению вычислительной мощности во время обучения. Это произошло в основном за счет масштабного самообучения. Однако появился новый подход, называемый масштабированием во время тестирования, который фокусируется на улучшении производительности за счет увеличения вычислений во время вывода.
Преимущества подхода
Модель OpenAI o1 подтвердила эффективность этого подхода, продемонстрировав улучшенные способности к рассуждению. Тем не менее, воспроизвести эти результаты оказалось сложно. Разработаны различные методы, такие как поиск Монте-Карло и обучение с подкреплением, но ни один из них не смог достичь поведения масштабирования во время тестирования, как в o1.
Методы решения проблемы
Разработаны различные методы для решения проблемы масштабирования во время тестирования. Последовательные подходы позволяют моделям генерировать последовательные попытки решения, где каждая итерация основывается на предыдущих результатах. Деревообразные методы поиска комбинируют последовательное и параллельное масштабирование, используя такие техники, как поиск с направленным лучом.
Подход REBASE
Подход REBASE использует модель вознаграждения для оптимизации поиска в дереве, показывая превосходные результаты по сравнению с методами на основе выборки. Эти методы сильно зависят от моделей вознаграждения, которые бывают двух типов: для оценки полных решений и для оценки отдельных шагов рассуждения.
Инновации в исследовании
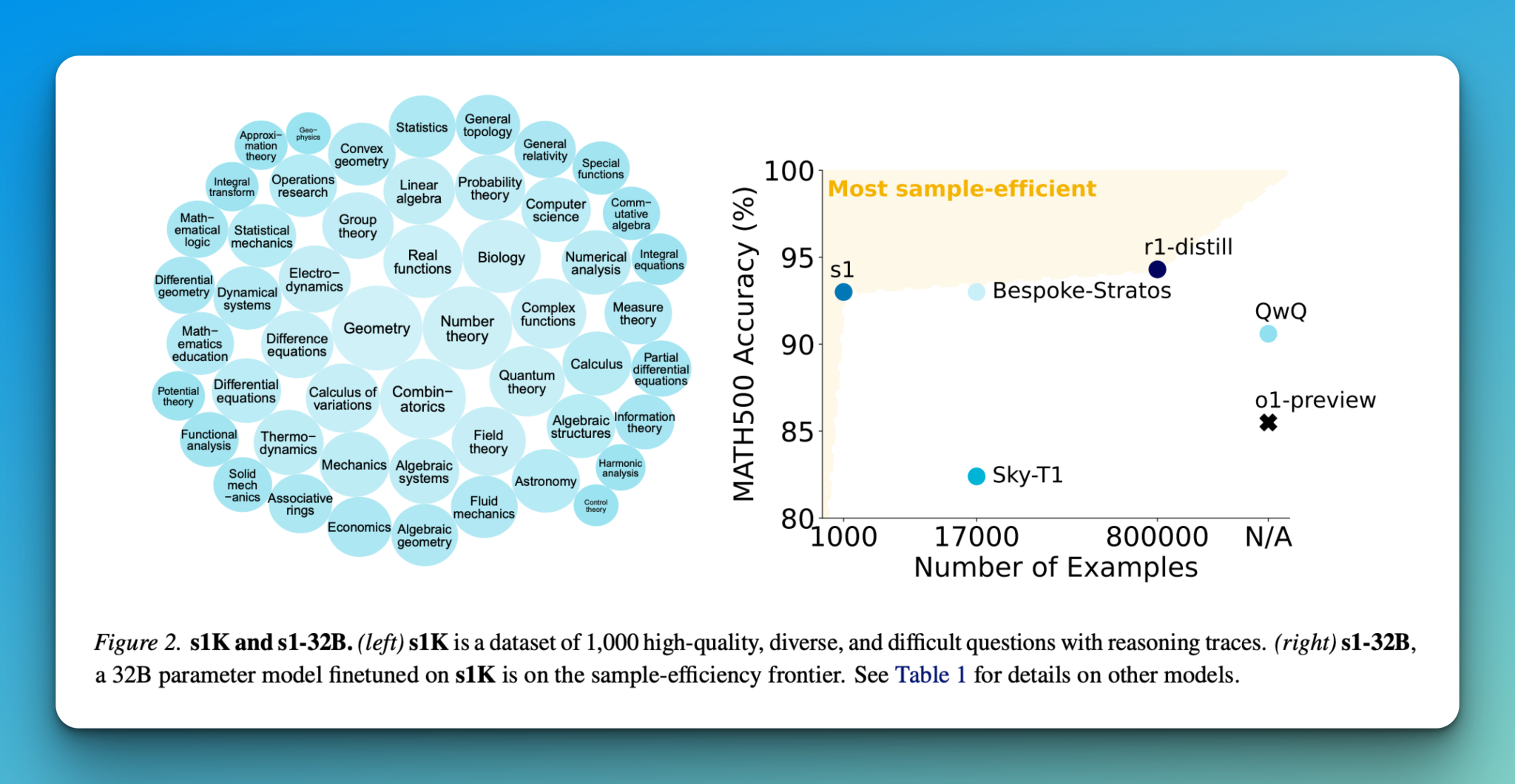
Исследователи из Стэнфордского университета и других учреждений предложили упрощенный подход для достижения масштабирования во время тестирования. Их метод основан на двух ключевых новшествах: тщательно подобранном наборе данных s1K и новой технике бюджетного принуждения.
Набор данных s1K
Набор данных s1K состоит из 1,000 вопросов с трассами рассуждений, выбранных по критериям сложности, разнообразия и качества. Бюджетное принуждение контролирует вычисления во время тестирования, позволяя модели пересматривать и корректировать свои рассуждения.
Результаты и эффективность
Модель s1-32B демонстрирует значительные улучшения производительности благодаря масштабированию во время тестирования с бюджетным принуждением. Она работает в более эффективной парадигме масштабирования по сравнению с базовой моделью Qwen2.5-32B.
Выводы
Эти исследования показывают, что супервизионная тонкая настройка с использованием всего 1,000 тщательно отобранных примеров может создать конкурентоспособную модель рассуждения. Внедрение техники бюджетного принуждения успешно воспроизводит поведение масштабирования во время тестирования.
Как использовать ИИ в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ), рассмотрите следующие шаги:
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Подберите подходящее решение из множества доступных вариантов ИИ.
- Внедряйте ИИ постепенно, начиная с небольших проектов и анализируя результаты.
Получите помощь
Если вам нужны советы по внедрению ИИ, пишите нам.
Попробуйте ИИ ассистент в продажах, который поможет отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























