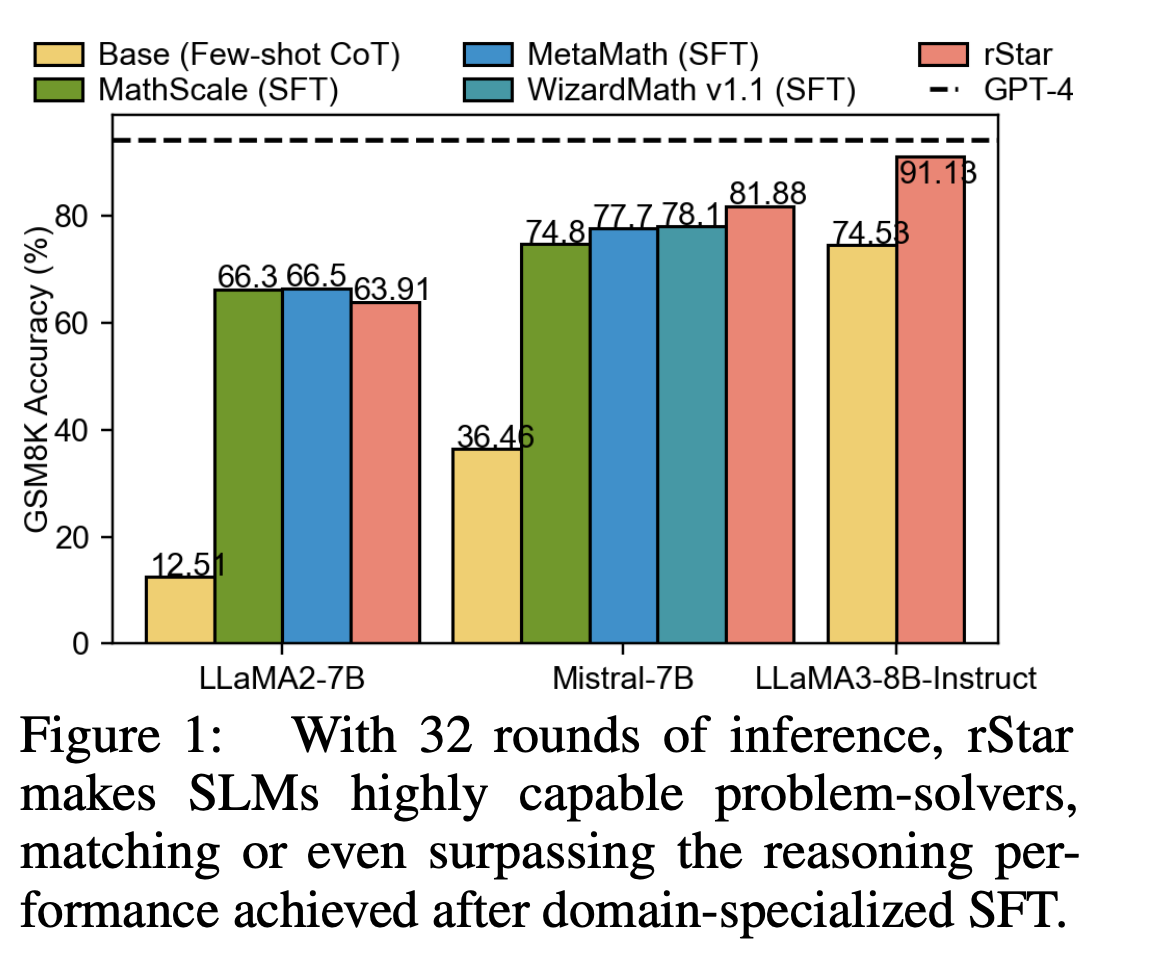
«`html
Self-play muTuAl Reasoning (rStar): Новый подход в области искусственного интеллекта, усиливающий способности малых языковых моделей в рассуждениях во время вывода без Fein-Tuning
Большие языковые модели (LLMs) сделали значительные шаги в различных приложениях, но по-прежнему сталкиваются с существенными проблемами в сложных задачах рассуждения. Например, даже продвинутые модели, такие как Mistral-7B, могут достигнуть только 36,5% точности на наборе данных GSM8K, несмотря на применение техник, таких как Chain-of-Thought (CoT).
Исследователи из Microsoft Research Asia и Гарвардского университета представили подход Self-play muTuAl Reasoning (rStar), который представляет собой надежное решение для улучшения способностей малых языковых моделей в рассуждениях во время вывода, без использования Fein-Tuning или более продвинутых моделей.
Решение rStar:
rStar решает проблемы, с которыми сталкиваются SLM через уникальный процесс самостоятельной генерации и дискриминации. Этот метод использует обычный алгоритм Монте-Карло для самостоятельной генерации рассуждения, но расширяет набор рассуждений для имитации человеческого поведения. Для руководства исследованием сгенерированных рассуждений rStar вводит процесс дискриминации, который использует вторую SLM в качестве дискриминатора для предоставления безнадзорной обратной связи о кандидатских рассуждениях.
Результаты:
1. Производительность на различных задачах рассуждения: rStar значительно улучшил способности SLM по решению проблем. Например, точность LLaMA2-7B на наборе данных GSM8K повысилась с 12,51% с использованием CoT до 63,91% с rStar, почти соответствуя производительности после Fein-Tuning.
2. Эффективность: rStar показал значительное улучшение точности рассуждения с помощью всего 2 прокатов на наборе данных GSM8K.
3. Производительность на сложных математических наборах данных: На GSM-Hard и MATH-500 rStar значительно улучшил точность рассуждения SLM, улучшив производительность по сравнению с современными методами базовой линии.
4. Ablation-исследования: генератор MCTS в rStar превзошел другие подходы, такие как RAP и Self-Consistency для различных моделей и задач.
5. Сравнение моделей: различные модели были протестированы в качестве дискриминаторов, причем GPT-4 достиг наивысшей точности (92,57%) на GSM8K, за которой последовал Phi3-Mini-Instruct (91,13%).
Эти результаты подчеркивают эффективность rStar в улучшении способностей рассуждения SLM на различных задачах и моделях, превзойдя существующие методы как по точности, так и по эффективности.
Подробнее о статье. Вся заслуга за это исследование принадлежит исследователям этого проекта.
«`
This is the HTML format of the given text with the requested simple and clear language, along with highlights of the practical solutions and value.

























