Metron: комплексный фреймворк ИИ для оценки пользовательской производительности в системах вывода крупных языковых моделей (LLM)
При оценке производительности систем вывода крупных языковых моделей (LLM) с использованием традиционных метрик возникают значительные вызовы. Метрики, такие как время до первого токена (TTFT) и время между токенами (TBT), не улавливают полного пользовательского опыта во время взаимодействий в реальном времени. В приложениях, таких как чат и перевод, отзывчивость прямо влияет на удовлетворение пользователей. Существует потребность в более тонком фреймворке оценки, который полностью охватывает сложности вывода крупных языковых моделей для обеспечения оптимального развертывания и производительности в реальных сценариях.
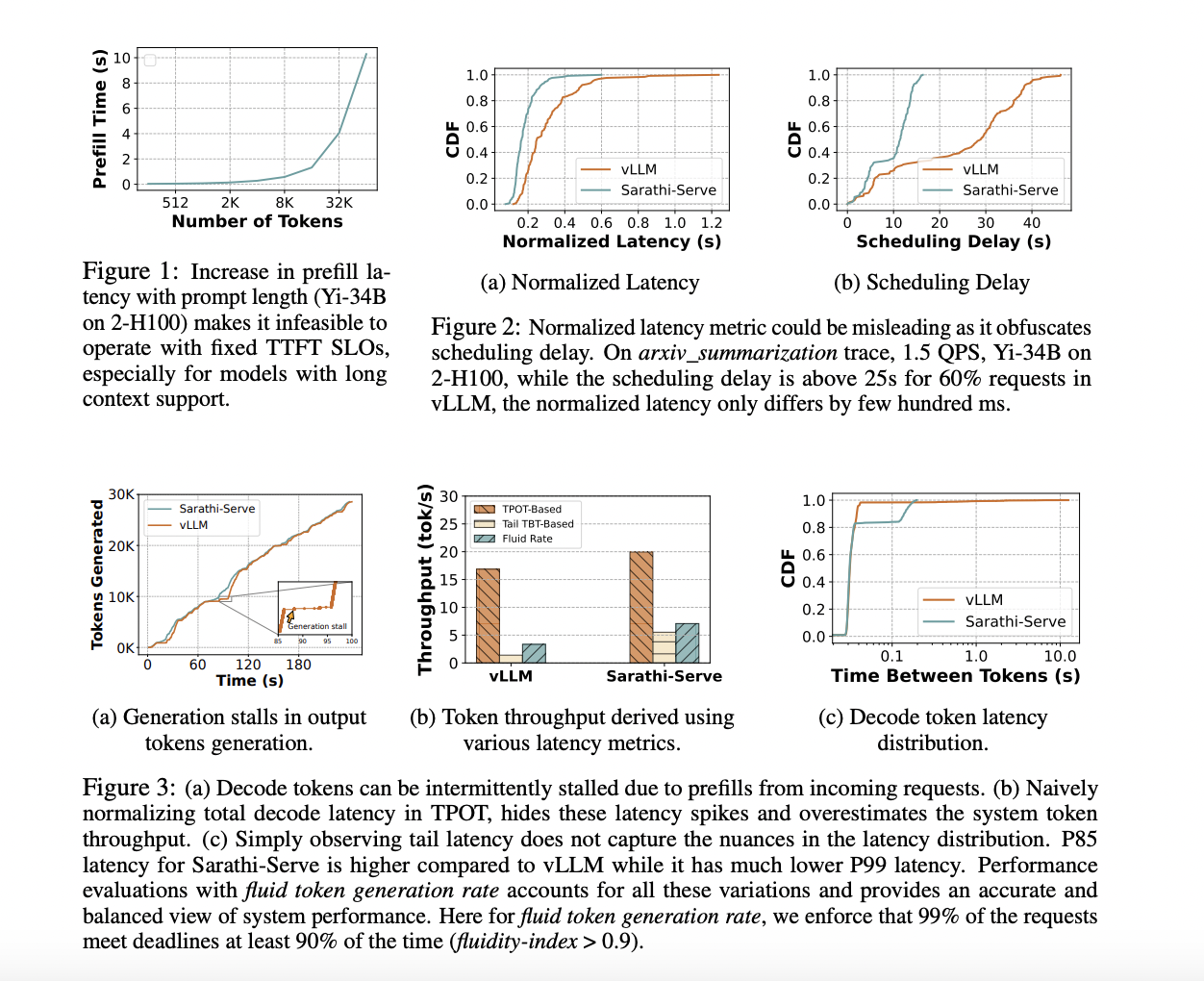
Текущие методы оценки производительности вывода LLM включают TTFT, TBT, нормализованную задержку и время на вывод одного токена (TPOT). Эти метрики оценивают различные аспекты задержек и пропускной способности, но оставляют пробелы в полном представлении пользовательского опыта. Например, TTFT и TBT фокусируются на задержках отдельных токенов без учета пропускной способности от начала до конца, в то время как нормализованные метрики затрудняют выявление проблем, таких как межтокенная джиттер и задержки планирования. Эти ограничения снижают их эффективность в приложениях реального времени, где поддержание плавной и последовательной скорости генерации токенов критично.
Команда исследователей из Института технологии Джорджии, Исследовательского центра Майкрософт в Индии и Лаборатории искусственного интеллекта Intel предлагают Metron, комплексный фреймворк оценки производительности. Metron представляет новые метрики, такие как индекс плавности и плавная скорость генерации токенов, которые улавливают тонкости взаимодействий в реальном времени с потоковыми выводами LLM. Эти метрики учитывают временные аспекты генерации токенов, обеспечивая более точное отражение производительности, ориентированной на пользователя. Устанавливая дедлайны на уровне токенов и измеряя долю соблюденных дедлайнов, индекс плавности предоставляет точное определение ограничений пользовательского опыта. Этот подход является значительным вкладом, предлагая более точный и ориентированный на пользователя метод оценки.
Метрика индекса плавности в Metron устанавливает дедлайны на генерацию токенов на основе желаемых значений TTFT и TBT, корректируя их в зависимости от длины запроса и наблюдаемой производительности системы. Этот метод учитывает задержки планирования и переменные скорости генерации токенов, обеспечивая плавный вывод. Фреймворк оценивает как открытые, так и проприетарные системы вывода LLM, применяя индекс плавности для измерения процента соблюденных дедлайнов и динамической коррекции дедлайнов в реальном времени. Этот метод предлагает комплексное представление о способности системы обрабатывать запросы пользователей без ущерба для отзывчивости.
Metron обеспечивает более точную оценку систем вывода LLM по сравнению с традиционными метриками. Индекс плавности и плавная скорость генерации токенов показывают значительные различия в пользовательском опыте, которые не улавливаются только TTFT или TBT. Например, оценка систем, таких как vLLM и Sarathi-Serve, продемонстрировала, что Sarathi-Serve достигает меньшего количества пропущенных дедлайнов и высокую плавность. Находки показывают, что Sarathi-Serve поддерживал индекс плавности > 0,9 для 99% запросов, достигая пропускной способности 600 токенов в секунду, в то время как vLLM показал 3-кратное ухудшение TBT из-за задержек генерации. Это демонстрирует эффективность Metron в выявлении различий в производительности и обеспечении лучшего пользовательского опыта в приложениях реального времени.

























