“`html
Arcee AI выпустила DistillKit: инновационный инструмент для создания эффективных малых языковых моделей
Arcee AI объявила о выпуске DistillKit, инновационного инструмента с открытым исходным кодом, разработанного для революционизации создания и распространения малых языковых моделей (SLM). Этот релиз соответствует постоянной миссии Arcee AI сделать ИИ более доступным и эффективным для исследователей, пользователей и бизнеса, стремящихся получить доступ к методам дистилляции с открытым исходным кодом и простым в использовании инструментам.
Введение в DistillKit
DistillKit – это проект с открытым исходным кодом, ориентированный на метод дистилляции моделей, позволяющий передавать знания от больших, ресурсоемких моделей к более маленьким и эффективным. Этот инструмент направлен на то, чтобы сделать передовые возможности ИИ доступными более широкой аудитории путем значительного снижения вычислительных ресурсов, необходимых для запуска этих моделей.
Методы дистилляции в DistillKit
DistillKit использует два основных метода передачи знаний: дистилляцию на основе логитов и дистилляцию на основе скрытых состояний.
Дистилляция на основе логитов: Этот метод включает передачу учителем (большой моделью) своих вероятностей вывода (логитов) модели ученику (более маленькой модели). Модель ученика учится не только правильным ответам, но и уверенности учителя в своих предсказаниях. Эта техника повышает способность модели ученика обобщать и эффективно выполнять задачи, подражая распределению вывода модели учителя.
Дистилляция на основе скрытых состояний: Модель ученика обучается воспроизводить промежуточные представления учителя в этом подходе. Соответствуя своей внутренней обработке модели учителя, модель ученика получает более глубокое понимание данных. Этот метод полезен для дистилляции между моделями с различными токенизаторами.
Основные выводы DistillKit
Эксперименты и оценки производительности DistillKit предоставляют несколько ключевых идей о его эффективности и потенциальных применениях:
Повышение производительности общего назначения: DistillKit продемонстрировал последовательное улучшение производительности на различных наборах данных и условиях обучения. Модели, обученные на подмножествах openhermes, WebInstruct-Sub и FineTome, показали обнадеживающие улучшения в таких бенчмарках, как MMLU и MMLU-Pro. Эти результаты указывают на значительные улучшения в усвоении знаний для SLM.
Повышение производительности в специфических областях: Целенаправленный подход к дистилляции привел к заметным улучшениям в задачах, специфичных для определенной области. Например, дистилляция Arcee-Agent в Qwen2-1.5B-Instruct с использованием тех же данных для обучения, что и у модели-учителя, привела к существенному улучшению производительности. Это показывает, что использование идентичных обучающих наборов данных для моделей-учителя и ученика может привести к более высоким улучшениям производительности.
Гибкость и универсальность: Возможность DistillKit поддерживать дистилляцию на основе логитов и скрытых состояний обеспечивает гибкость в выборе архитектуры модели. Эта универсальность позволяет исследователям и разработчикам настраивать процесс дистилляции под конкретные требования.
Эффективность и оптимизация ресурсов: DistillKit снижает вычислительные ресурсы и энергопотребление, необходимые для развертывания ИИ, позволяя создавать более маленькие и эффективные модели. Это делает передовые возможности ИИ более доступными и способствует устойчивым практикам исследований и разработки ИИ.
Сотрудничество с открытым исходным кодом: Открытый характер DistillKit приглашает сообщество вносить свой вклад в его дальнейшее развитие. Этот совместный подход способствует инновациям и улучшениям, побуждая исследователей и разработчиков исследовать новые методы дистилляции, оптимизировать процессы обучения и улучшать эффективность использования памяти.
Результаты производительности
Эффективность DistillKit была тщательно проверена через серию экспериментов для оценки ее влияния на производительность и эффективность моделей. Эти эксперименты сосредоточились на различных аспектах, включая сравнение методов дистилляции, производительность дистиллированных моделей по сравнению с моделями-учителями и приложения дистилляции в специфических областях.
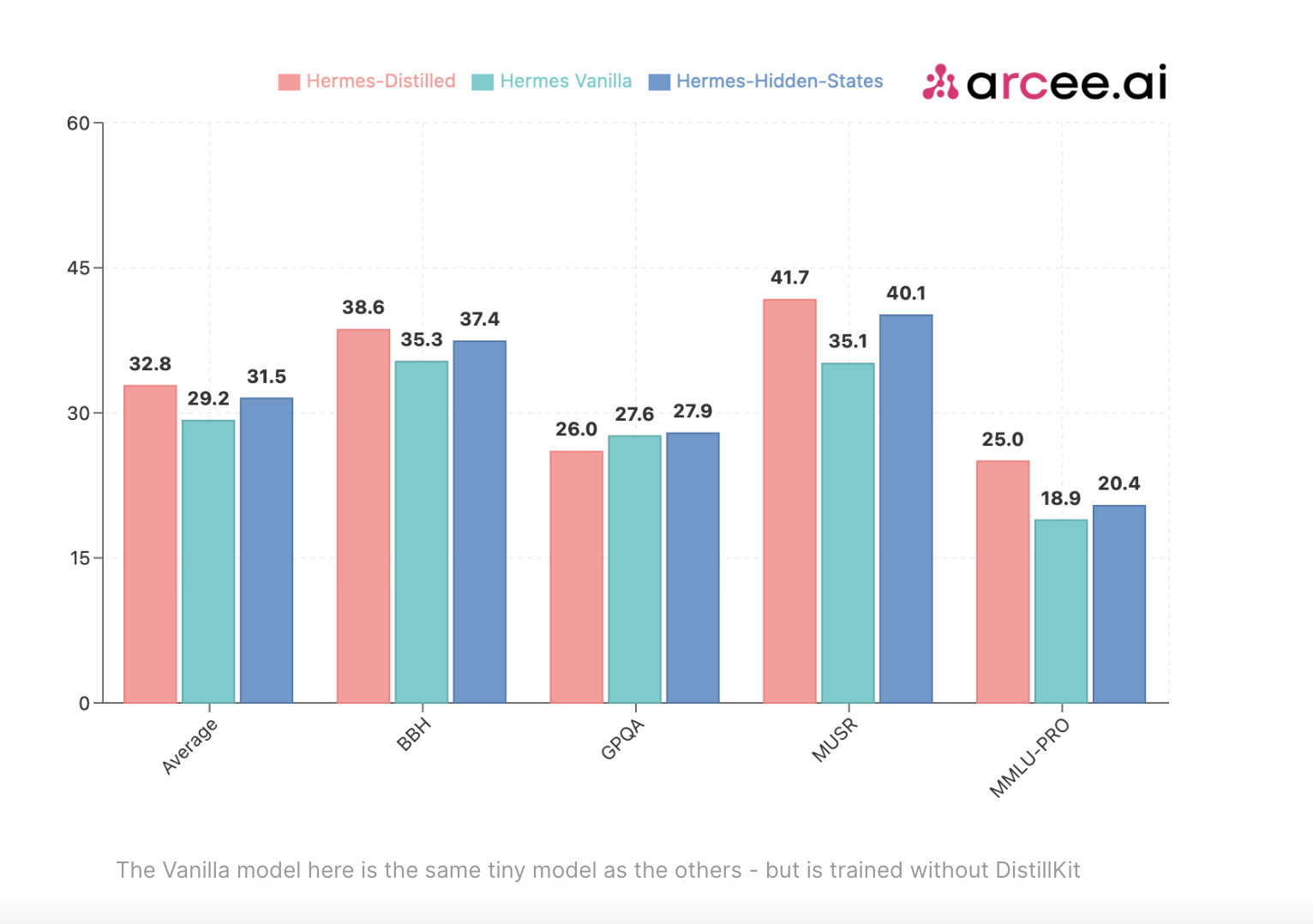
Сравнение методов дистилляции: Первый набор экспериментов сравнивал производительность различных моделей, улучшенных с помощью методов дистилляции на основе логитов и скрытых состояний, по сравнению с обычным методом надзорного дообучения (SFT). Используя Arcee-Spark в качестве модели-учителя, знания были дистиллированы в модели Qwen2-1.5B-Base. Результаты продемонстрировали значительное улучшение производительности для дистиллированных моделей по сравнению с базовым вариантом только SFT по таким основным бенчмаркам, как BBH, MUSR и MMLU-PRO.
Дистилляция на основе логитов: Подход на основе логитов превзошел метод на основе скрытых состояний по большинству бенчмарков, демонстрируя свою способность более эффективно улучшать производительность ученика путем более эффективной передачи знаний.
Дистилляция на основе скрытых состояний: Хотя этот метод немного уступал методу на основе логитов в общей производительности, он все равно обеспечивал существенные улучшения по сравнению с вариантом только SFT, особенно в ситуациях, требующих дистилляции между моделями различных архитектур.
Эти результаты подчеркивают надежность методов дистилляции, реализованных в DistillKit, и подчеркивают их потенциал для значительного повышения эффективности и точности более маленьких моделей.
Эффективность в общих областях: Дополнительные эксперименты оценили эффективность дистилляции на основе логитов в общей области. Дистиллированная модель 1.5B, обученная на подмножестве WebInstruct-Sub, была сравнена с моделью-учителем Arcee-Spark и базовой моделью Qwen2-1.5B-Instruct. Дистиллированная модель последовательно улучшила производительность по всем метрикам, демонстрируя результаты, сравнимые с моделью-учителем, особенно на бенчмарках MUSR и GPQA. Этот эксперимент подтвердил способность DistillKit создавать высокоэффективные модели, сохраняющие большую часть производительности модели-учителя, при этом значительно меньшие и менее ресурсоемкие.
Дистилляция для специфических областей: Потенциал DistillKit для задач, специфичных для определенной области, также был изучен через дистилляцию модели Arcee-Agent в модели Qwen2-1.5B-Instruct. Arcee-Agent, модель, специализированная на вызове функций и использовании инструментов, выступала в качестве модели-учителя. Результаты показали значительное улучшение производительности и подчеркнули эффективность использования тех же обучающих данных для моделей-учителя и ученика. Этот подход улучшил общие возможности дистиллированных моделей и оптимизировал их для конкретных задач.
Влияние и будущие направления
Выпуск DistillKit готовит почву для создания более маленьких и эффективных моделей, делая передовые возможности ИИ доступными для различных пользователей и приложений. Эта доступность критична для бизнеса и частных лиц, которым может не хватать ресурсов для развертывания масштабных моделей ИИ. Меньшие модели, созданные с помощью DistillKit, предлагают несколько преимуществ, включая снижение энергопотребления и операционных расходов. Эти модели могут быть развернуты непосредственно на локальных устройствах, улучшая конфиденциальность и безопасность за счет минимизации необходимости передачи данных на облачные серверы. Arcee AI планирует продолжать улучшать DistillKit, добавляя дополнительные функции и возможности. Будущие обновления будут включать продвинутые методы дистилляции, такие как Continued Pre-Training (CPT) и Direct Preference Optimization (DPO).
Заключение
DistillKit от Arcee AI является значительным событием в области дистилляции моделей, предлагая надежный, гибкий и эффективный инструмент для создания SLM. Результаты производительности экспериментов и основные выводы подчеркивают потенциал DistillKit для революционизации развертывания ИИ, делая передовые модели более доступными и практичными. Преданность Arcee AI открытым исследованиям и сотрудничеству с сообществом гарантирует, что DistillKit будет продолжать развиваться, внедряя новые методы и оптимизации, чтобы соответствовать постоянно меняющимся требованиям технологий ИИ. Arcee AI также приглашает сообщество внести свой вклад в проект, разрабатывая новые методы дистилляции для улучшения процессов обучения и оптимизации использования памяти.
“`











