Преимущества Системы Cerebras в области искусственного интеллекта
Cerebras Systems установила новый стандарт в области искусственного интеллекта (ИИ) с запуском уникального решения для ИИ-вывода. Это предложение обеспечивает невиданные скорость и эффективность при обработке больших моделей языка (LLM). Новое решение, названное Cerebras Inference, разработано для удовлетворения сложных и растущих потребностей ИИ-приложений, особенно тех, которые требуют реального времени и выполнения сложных многоэтапных задач.
Беспрецедентная скорость и эффективность
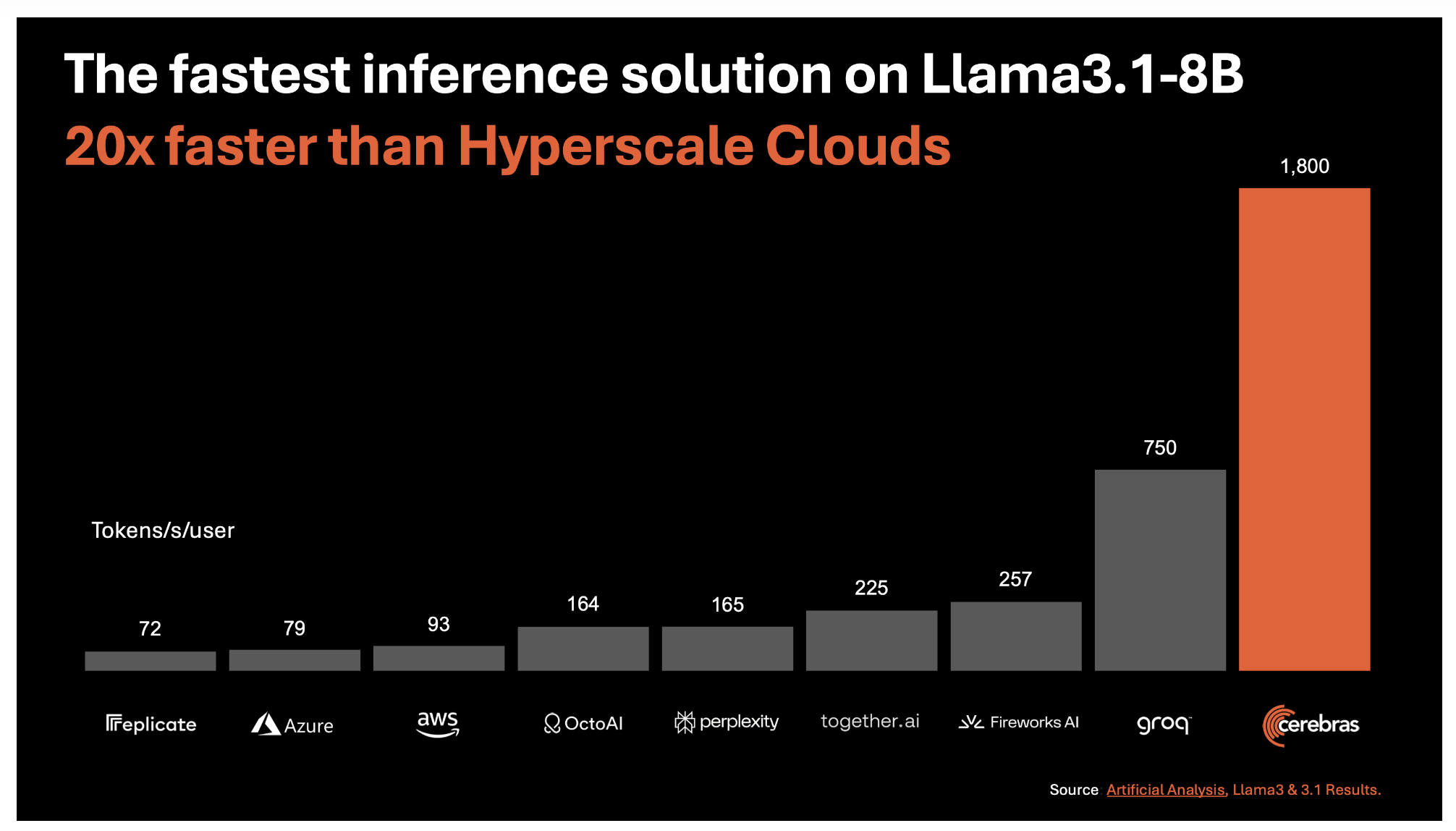
В основе Cerebras Inference лежит третьего поколения Wafer Scale Engine (WSE-3), который обеспечивает самое быстрое решение для ИИ-вывода на сегодняшний день. Эта технология обеспечивает выдачу впечатляющих 1 800 токенов в секунду для моделей Llama3.1 8B и 450 токенов в секунду для моделей Llama3.1 70B. Эти скорости примерно в 20 раз выше, чем у традиционных решений на основе GPU в облаке гипермасштабных сред. Этот скачок в производительности не только касается сырой скорости, но и предлагается по доле стоимости: цена составляет всего 10 центов за миллион токенов для модели Llama 3.1 8B и 60 центов за миллион токенов для модели Llama 3.1 70B.
Решение проблемы пропускной способности памяти
Одной из основных проблем в ИИ-выводе является необходимость в обширной пропускной способности памяти. Cerebras преодолела эту проблему, напрямую интегрировав огромные 44 ГБ SRAM на чип WSE-3, устраняя необходимость во внешней памяти и значительно увеличивая пропускную способность памяти. WSE-3 предлагает поразительные 21 петабайт в секунду агрегированной пропускной способности памяти, в 7 000 раз больше, чем у GPU Nvidia H100. Этот прорыв позволяет Cerebras Inference легко обрабатывать большие модели, обеспечивая более быстрый и точный вывод.
Сохранение точности с 16-битной точностью
Еще одним важным аспектом Cerebras Inference является его стремление к точности. В отличие от некоторых конкурентов, которые снижают точность веса до 8 бит для достижения более высокой скорости, Cerebras сохраняет исходную 16-битную точность на протяжении всего процесса вывода. Это гарантирует, что результаты модели будут максимально точными, что критично для задач, требующих высокой точности, таких как математические вычисления и сложные логические задачи.
Стратегические партнерства и будущее развитие
Cerebras также строит крепкую экосистему вокруг своего решения для ИИ-вывода. Она заключила партнерские соглашения с ведущими компаниями в отрасли ИИ, включая Docker, LangChain, LlamaIndex и Weights & Biases, чтобы предоставить разработчикам необходимые инструменты для быстрой и эффективной разработки и внедрения ИИ-приложений.
Влияние на ИИ-приложения
Влияние высокой скорости работы Cerebras Inference простирается далеко за пределы традиционных ИИ-приложений. За счет значительного сокращения времени обработки Cerebras позволяет более сложные рабочие процессы ИИ и улучшает реальное время в моделях LLM. Это может революционизировать отрасли, зависящие от ИИ, от здравоохранения до финансов, позволяя более быстрое и точное принятие решений.
Заключение
Запуск компанией Cerebras Systems самого быстрого в мире решения для ИИ-вывода представляет собой значительный прорыв в технологии ИИ. Cerebras Inference готов переопределить возможности в области ИИ, объединяя беспрецедентную скорость, эффективность и точность. Инновации, такие как Cerebras Inference, сыграют ключевую роль в формировании будущего технологий.

























