FLAMe: Надежная и эффективная модель для оценки крупных языковых моделей
Оценка крупных языковых моделей (LLM) становится все более сложной из-за их сложности и универсальности. Гарантирование надежности и качества результатов этих моделей критически важно для развития технологий и приложений искусственного интеллекта. Исследователям необходима помощь в разработке надежных методов оценки для оценки точности и беспристрастности результатов LLM, учитывая субъективный, несогласованный и дорогостоящий характер человеческих оценок.
FLAMe: Новый подход к оценке LLM
Команда исследователей из Google DeepMind, Google и UMass Amherst представила FLAMe — семейство моделей Foundational Large Autorater, разработанных для улучшения оценки LLM. FLAMe использует большую и разнообразную коллекцию задач оценки качества, производных от человеческих оценок, для обучения и стандартизации авторейтеров. FLAMe обучается с использованием метода многозадачной дообучения на более чем 100 задачах оценки качества, охватывающих более 5 миллионов человеческих оценок. Этот подход позволяет FLAMe обобщаться на новые задачи и превосходить существующие модели, такие как GPT-4 и Claude-3.
Обучение FLAMe включает тщательный процесс сбора и стандартизации данных. Исследовательская группа отобрала человеческие оценки из предыдущих исследований, сосредоточившись на задачах, таких как качество машинного перевода и инструкции для искусственного интеллекта. Этот обширный набор данных был затем преобразован в единый текстовый формат, где каждая задача оценки качества была преобразована в пары ввод-цель. Входы содержат контексты, специфичные для задачи, а цели содержат ожидаемые человеческие оценки. Благодаря обучению на этом большом и разнообразном наборе данных, FLAMe учится надежным шаблонам человеческого суждения, минимизируя влияние шумных или низкокачественных данных.
Преимущества и применимость FLAMe
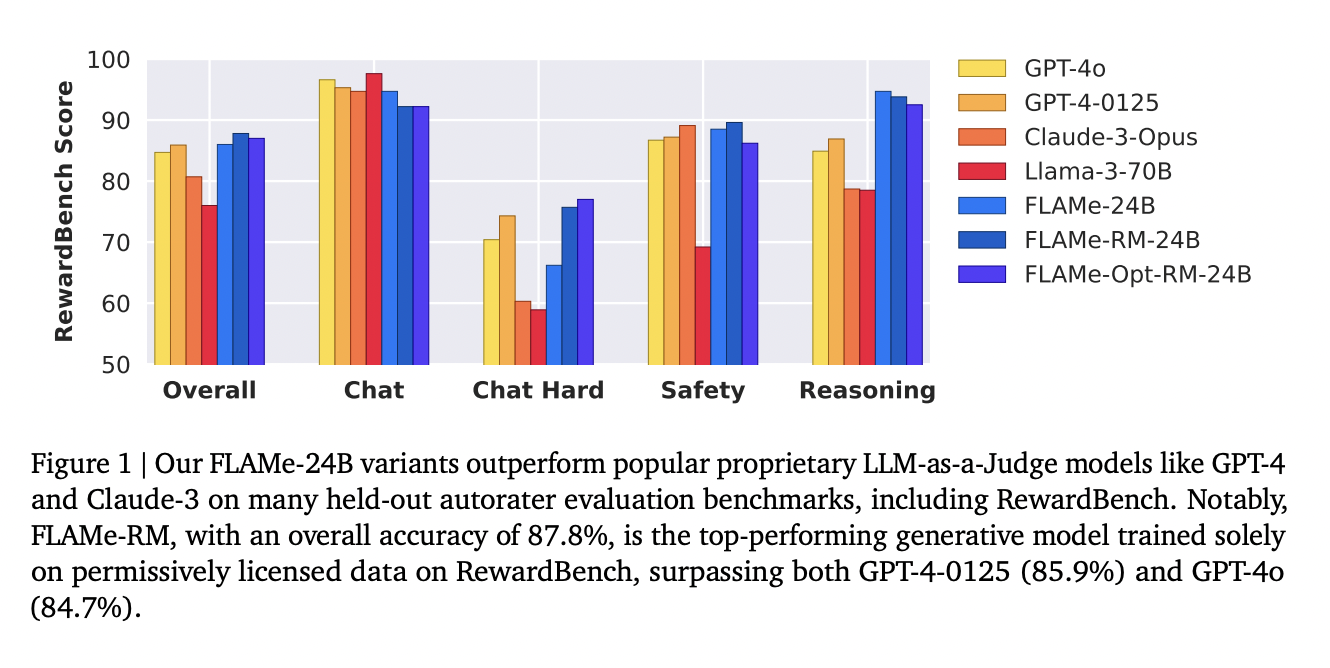
Производительность FLAMe впечатляет на различных бенчмарках. Модель FLAMe-RM-24B, вариант, настроенный для оценки моделирования вознаграждения, достигла точности 87,8% на RewardBench, превосходя как GPT-4-0125 (85,9%), так и GPT-4o (84,7%). На бенчмарке CoBBLEr bias, FLAMe проявляет значительно меньший уровень предвзятости по сравнению с другими моделями авторейтеров. Кроме RewardBench, производительность FLAMe впечатляет и на других бенчмарках. Модели FLAMe превосходят существующие LLM в 8 из 12 автоматизированных бенчмарков оценки качества, охватывающих 53 задачи оценки качества. Это включает задачи, такие как сравнение резюме, оценка полезности и оценка фактической точности.
FLAMe-Opt-RM, эффективный вариант, оптимизирует многозадачную смесь для оценки моделирования вознаграждения с использованием новой стратегии дообучения tail-patch. Этот метод позволяет достичь конкурентоспособной производительности на RewardBench с примерно в 25 раз меньшим количеством обучающих точек данных.
В заключение, FLAMe представляет собой значительный шаг в оценке крупных языковых моделей, обеспечивая надежность, беспристрастность и высокое качество их результатов. Это развитие готово улучшить разработку и внедрение технологий искусственного интеллекта.

























