Введение в алгоритм BC-MAX от Google AI
Использование методов обучения с подкреплением (RL) в реальных приложениях сталкивается с двумя основными проблемами. Во-первых, постоянное взаимодействие и обновления в RL требуют больших инженерных затрат на масштабные системы, которые обычно работают со статичными моделями машинного обучения. Во-вторых, алгоритмы RL часто начинают с нуля, полагаясь только на информацию, полученную в ходе взаимодействий, что ограничивает их эффективность и адаптивность.
Проблемы и их решения
Современные методы обучения с подкреплением включают цикл онлайн-взаимодействия и обновления, который может быть неэффективен для крупных систем. Многие методы RL зависимы от оценки функции ценности и требуют доступа к динамике марковских процессов, что часто делает их неподходящими для сценариев с агрегированными сигналами вознаграждения.
Чтобы решить эти проблемы, исследователи разработали алгоритм, основанный на имитационном обучении, который использует траектории из нескольких базовых политик для создания новой политики, превосходящей лучшие комбинации этих базовых политик. Это значительно снижает сложность выборки и повышает производительность, используя существующие данные.
Методы и результаты
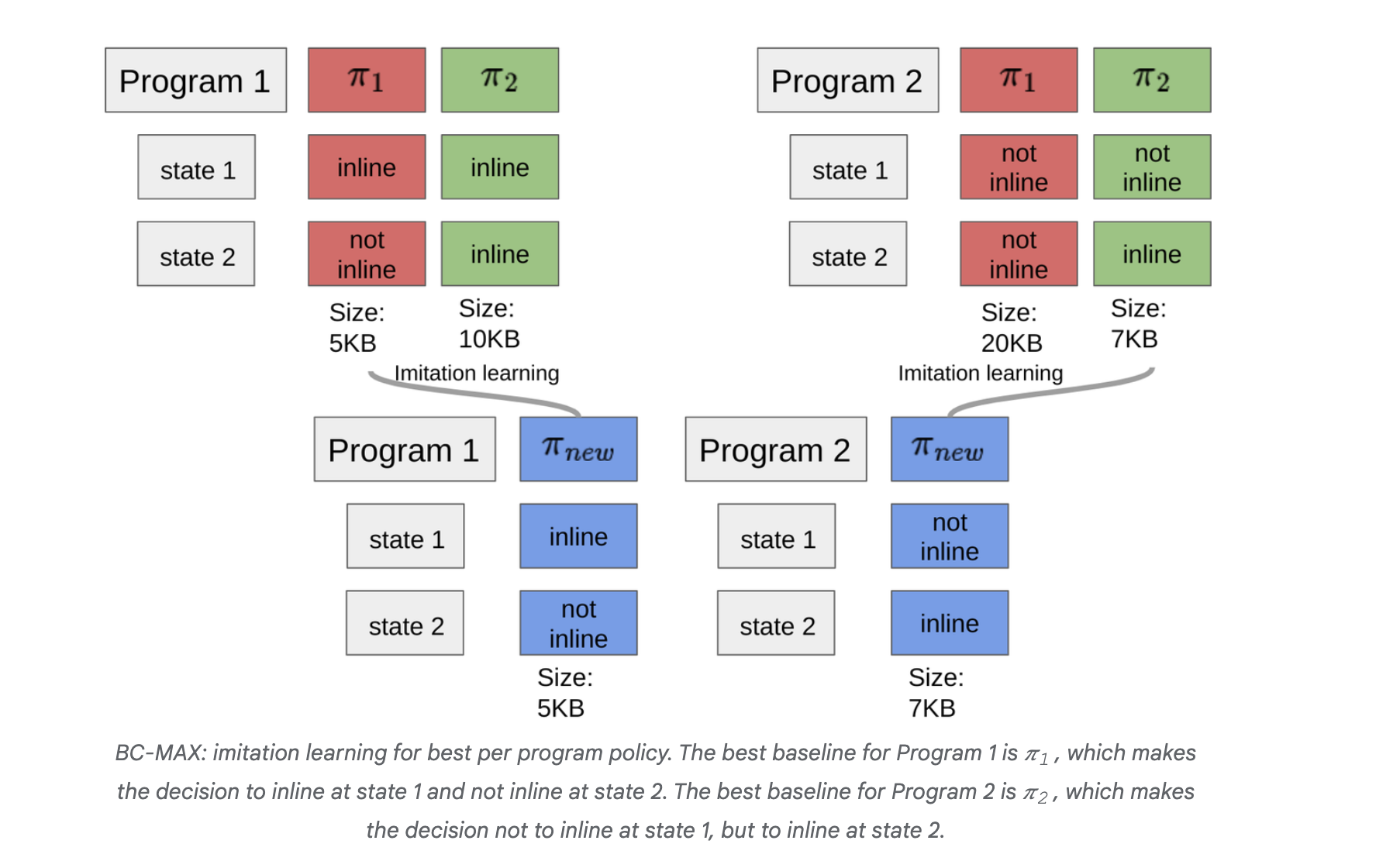
Исследователи из Google AI предложили метод, который включает сбор траекторий из K базовых политик, каждая из которых превосходит в разных частях состояния. Предлагаемый алгоритм BC-MAX выбирает траекторию с наибольшим кумулятивным вознаграждением и клонирует её, сосредоточившись на сопоставлении оптимальных последовательностей действий. Этот подход оптимизирует обучение с помощью ограниченных данных о вознаграждениях.
Алгоритм был применен для оптимизации компилятора, показывая, что новая политика превосходит начальную, изученную с использованием стандартного RL. Результаты показывают, что BC-MAX эффективно использует предыдущие политики, добиваясь хороших результатов с минимальными взаимодействиями с окружающей средой.
Выводы
Исследование представляет новый алгоритм имитационного обучения BC-MAX, который эффективно использует несколько базовых политик для оптимизации решений по инлайнингу компилятора. Этот метод показывает большую эффективность и снижает сложность выборки, что особенно важно для задач оптимизации компилятора.
Практическое применение ИИ в бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ и оставалась в числе лидеров, важно эффективно использовать такие решения:
- Проанализируйте, как ИИ может изменить вашу работу и выявите возможности для автоматизации.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Подберите подходящее решение ИИ, начиная с небольших проектов и анализируя результаты.
Дополнительные ресурсы
Если вам нужны советы по внедрению ИИ, пишите нам. Попробуйте ИИ ассистента в продажах на нашем сайте. Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























