Разработка терапевтических средств с помощью ИИ
Разработка новых лекарств — это дорогостоящий и длительный процесс, который может занять 10-15 лет и стоить до 2 миллиардов долларов. Большинство кандидатов на лекарства не проходят клинические испытания. Успешное лекарство должно соответствовать множеству критериев, таких как взаимодействие с целевыми молекулами, отсутствие токсичности и подходящая фармакокинетика.
Решения с использованием ИИ
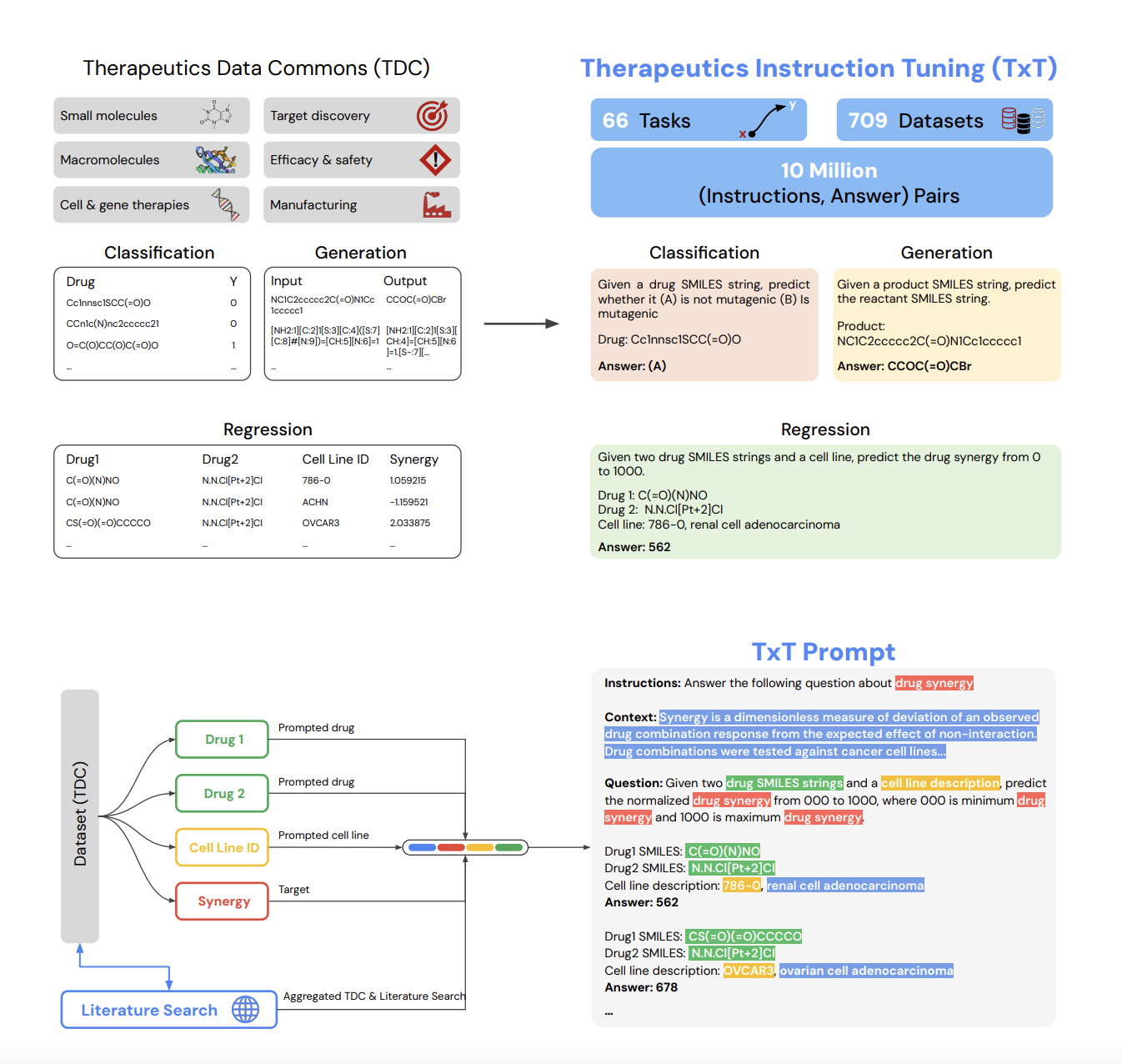
Современные модели ИИ сосредоточены на специализированных задачах, но их ограниченный подход может снижать эффективность. Therapeutics Data Commons (TDC) предлагает наборы данных, которые помогают моделям ИИ предсказывать свойства лекарств. Однако эти модели работают независимо друг от друга.
Модели LLM (large language models), которые хорошо справляются с множеством задач, могут улучшить разработку терапевтических средств, обучаясь на различных задачах с помощью единого подхода.
Преимущества Tx-LLM
Исследователи из Google представили Tx-LLM, универсальную языковую модель, настроенную на выполнение различных терапевтических задач. Она обучена на 709 наборах данных, охватывающих 66 функций в процессе открытия лекарств. Tx-LLM использует единый набор весов для обработки различных химических и биологических сущностей, таких как маломолекулы, белки и нуклеиновые кислоты.
Модель показывает конкурентоспособные результаты на 43 задачах и превосходит лучшие существующие решения на 22 из них. Tx-LLM особенно эффективна в задачах, которые объединяют молекулярные представления с текстом.
Сбор данных TxT
Исследователи собрали набор данных TxT, содержащий 709 наборов данных для открытия лекарств. Каждый набор данных был подготовлен для настройки инструкций и включал инструкции, контекст, вопросы и ответы. Задачи включали бинарную классификацию, регрессию и генерацию.
Потенциал и ограничения
Tx-LLM — это первая LLM, обученная на разнообразных наборах данных TDC. Интересно, что обучение на наборах данных, не связанных с маломолекулярными соединениями, таких как белки, улучшило результаты на задачах с маломолекулами. Хотя общие LLM испытывают трудности с специализированными химическими задачами, Tx-LLM преуспела в регрессии.
Однако Tx-LLM все еще находится на стадии исследования и требует дальнейшего улучшения и проверки для более широкого применения.
Как внедрить ИИ в вашу компанию
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, используйте решения, такие как Tx-LLM. Проанализируйте, как ИИ может изменить вашу работу, определите ключевые показатели эффективности (KPI), которые вы хотите улучшить с помощью ИИ.
Подберите подходящее решение и внедряйте ИИ постепенно. Начните с небольшого проекта, анализируйте результаты и расширяйте автоматизацию на основе полученных данных.
Если вам нужны советы по внедрению ИИ, пишите нам.
Попробуйте ИИ ассистента в продажах, который помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























