«`html
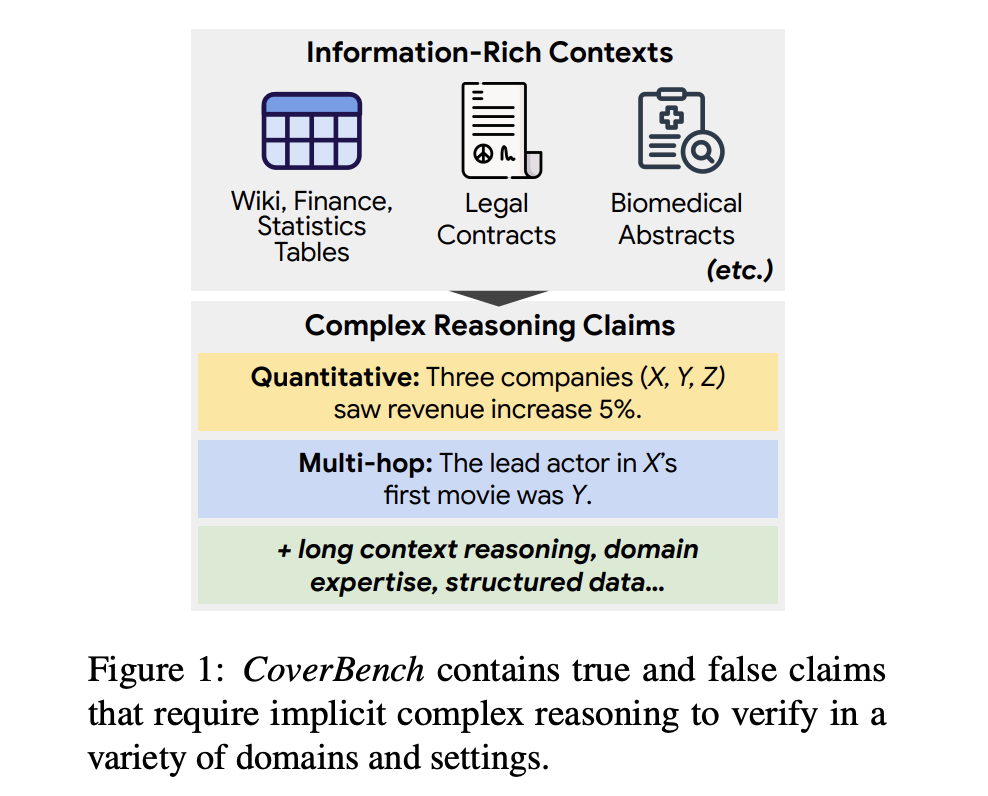
Google AI Introduces CoverBench: A Challenging Benchmark Focused on Verifying Language Model LM Outputs in Complex Reasoning Settings
Одной из основных задач исследований в области искусственного интеллекта (ИИ) является проверка правильности выводов языковых моделей (LMs), особенно в контекстах, требующих сложного рассуждения. Поскольку LMs все чаще используются для сложных запросов, требующих множества логических шагов, предметной экспертизы и количественного анализа, обеспечение точности и надежности этих моделей имеет решающее значение. Эта задача особенно важна в областях финансов, права и биомедицины, где неправильная информация может привести к серьезным негативным последствиям.
Практические решения и ценность
Методы проверки выводов LM включают факт-чекинг и техники естественного языка (NLI). Однако существующие методы имеют ограничения, такие как высокая вычислительная сложность, зависимость от больших объемов размеченных данных и недостаточная производительность в задачах, требующих длительного рассуждения или многократных выводов. CoverBench представляет собой бенчмарк, специально разработанный для оценки сложной проверки утверждений в различных областях и типах рассуждений. Он включает разнообразный набор задач, требующих многократных выводов, понимания длинного контекста и количественного анализа. Это новаторский подход позволяет провести всестороннюю оценку возможностей проверки LM, выявить области, требующие улучшения, и установить более высокий стандарт для задач проверки утверждений.
Комплексная оценка CoverBench показывает, что текущие конкурентоспособные LMs значительно затрудняются с представленными задачами, достигая производительности, близкой к случайной базовой линии во многих случаях. Самые производительные модели, такие как Gemini 1.5 Pro, достигли значения Macro-F1 в 62,1, что указывает на значительное пространство для улучшения. Эти результаты подчеркивают сложности, с которыми сталкиваются LMs в сложной проверке утверждений и значительные возможности для развития в этой области.
В заключение, CoverBench значительно способствует исследованиям в области ИИ, предоставляя сложный бенчмарк для проверки сложных утверждений. Он преодолевает ограничения существующих наборов данных, предлагая разнообразный набор задач, требующих многократных выводов, понимания длинного контекста и количественного анализа. Тщательная оценка бенчмарка показывает, что текущие LMs имеют значительное пространство для улучшения в этих областях. CoverBench устанавливает новый стандарт для проверки утверждений, расширяя границы того, что LMs могут достичь в сложных задачах рассуждения.
«`

























