Google AI представляет DataGemma: набор открытых моделей, использующих Data Commons через Retrieval Interleaved Generation (RIG) и Retrieval Augmented Generation (RAG)
Google представил инновацию под названием DataGemma, которая призвана решить одну из основных проблем современного искусственного интеллекта: галлюцинации в больших языковых моделях. Галлюцинации возникают, когда ИИ уверенно генерирует информацию, которая либо неверна, либо вымышлена. Эти неточности могут подрывать полезность ИИ, особенно для исследований, разработки политики или других важных процессов принятия решений.
Практические решения и ценность
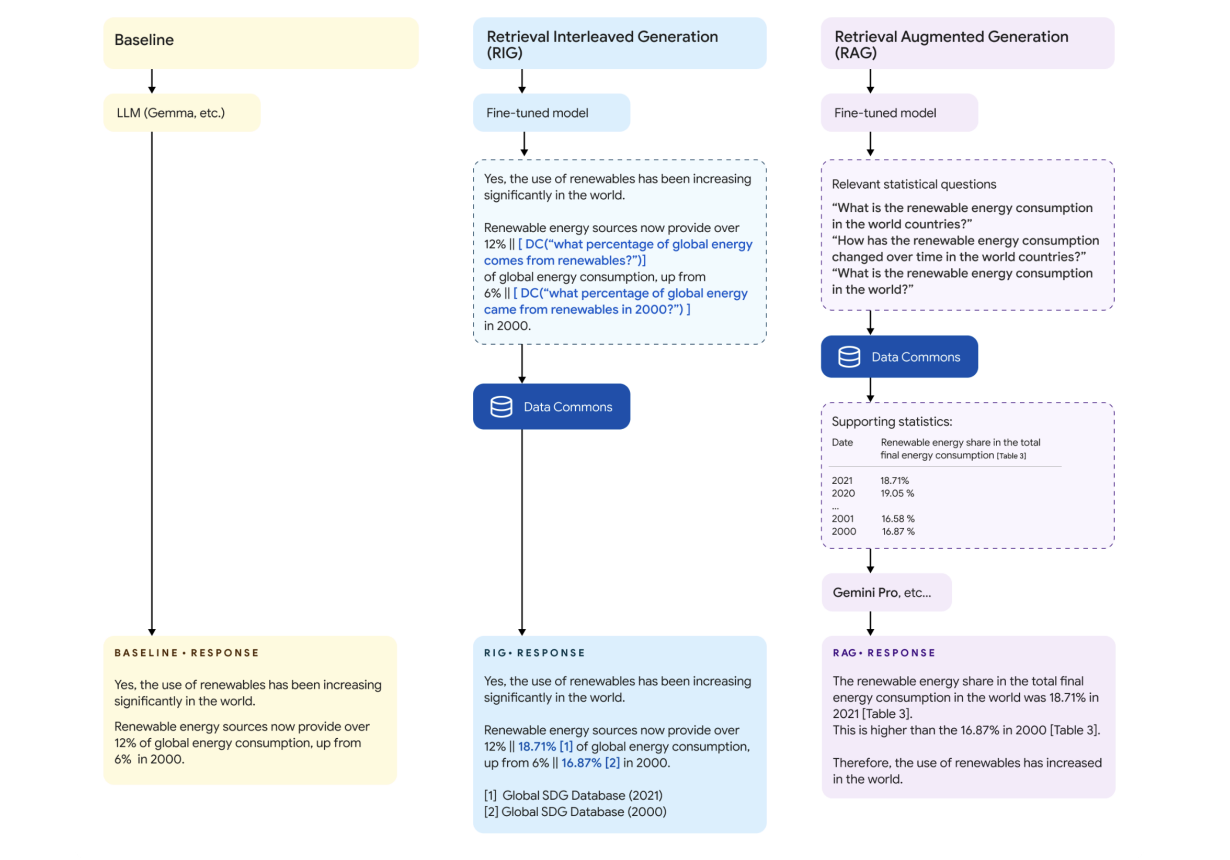
DataGemma использует обширные ресурсы Data Commons для закрепления больших языковых моделей в реальном мире, статистических данных. Это способствует улучшению точности и надежности контента, создаваемого ИИ.
Модели DataGemma-RAG-27B-IT и DataGemma-RIG-27B-IT представляют собой передовые достижения в методологиях Retrieval-Augmented Generation (RAG) и Retrieval-Interleaved Generation (RIG). Они предназначены для задач, требующих высокой точности и обоснованности, что делает их идеальными для областей исследований, разработки политики и бизнес-аналитики.
Google Data Commons — это обширный репозиторий общедоступных и надежных данных, содержащий более 240 миллиардов точек данных по многим статистическим переменным из таких надежных источников, как Организация Объединенных Наций, Всемирная организация здравоохранения и другие национальные бюро переписи населения. Это ценный инструмент для получения точных выводов.
Методологии RIG и RAG обеспечивают улучшение точности и фактичности больших языковых моделей. Они интегрируют проверку данных из надежных источников и обогащение контекстной информацией для создания более информативных и меньше подверженных галлюцинациям ответов.
Google уверен, что улучшение фактической точности, достигнутое через DataGemma, сделает инструменты на основе ИИ более надежными и незаменимыми для принятия обоснованных решений на основе данных.
Выпущенная Google DataGemma представляет собой значительный шаг в направлении создания более надежных и фактически обоснованных больших языковых моделей, что важно для обеспечения того, чтобы ИИ предоставлял пользователям точную информацию.
В целом, DataGemma представляет собой инновационный шаг в решении проблем галлюцинаций ИИ путем закрепления больших языковых моделей в обширных, авторитетных наборах данных Data Commons. Это значительный шаг в направлении обеспечения того, чтобы ИИ стал надежным партнером в исследованиях, принятии решений и открытии знаний.

























