Что такое обучение с подкреплением?
Обучение с подкреплением (RL) обучает агентов максимизировать вознаграждения, взаимодействуя с окружающей средой. Существует два основных типа RL: онлайн RL и безмодельное RL (MFRL).
Как работает обучение с подкреплением?
Онлайн RL чередует действия, сбор наблюдений и вознаграждений с обновлением стратегий на основе полученного опыта. Безмодельное RL требует обширного сбора данных.
Модельное RL
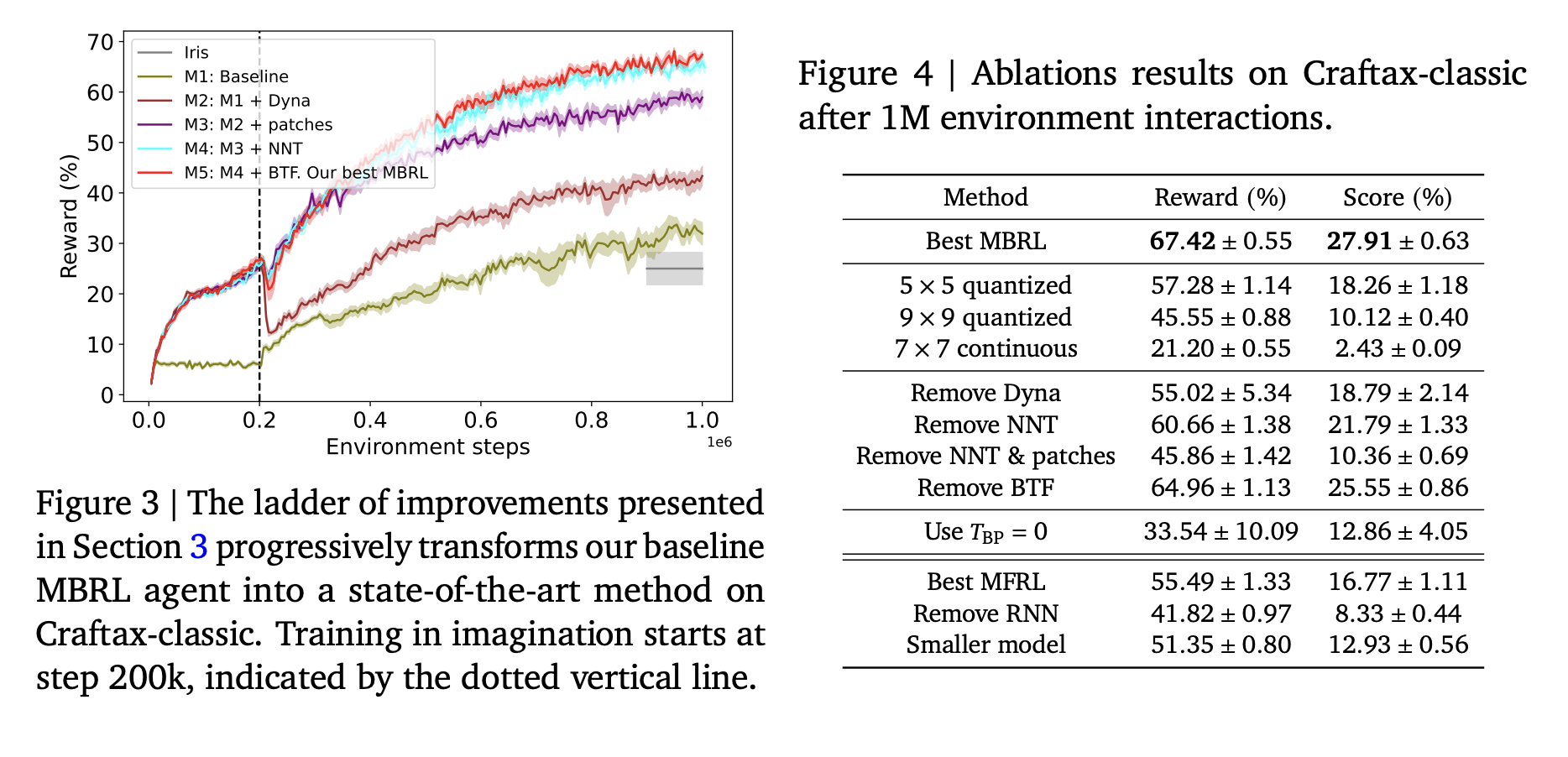
Модельное RL (MBRL) учится на основе модели мира для планирования в воображаемой среде, что снижает потребность в больших объемах данных. Исследования используют различные среды, такие как Crafter, для тестирования навыков агентов.
Новые достижения в MBRL
Исследователи из Google DeepMind представили новый метод MBRL, который устанавливает новые рекорды в сложной 2D игре Craftax-classic. Их подход достиг 67,42% вознаграждения за 1M шагов, что превышает предыдущие достижения.
Ключевые улучшения
- Введение надежного безмодельного базового метода.
- Использование токенизации для обработки изображений.
- Эффективное предсказание токенов с помощью блокового обучения.
Преимущества применения ИИ
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ), используйте достижения Google DeepMind для повышения эффективности.
Практические шаги
- Определите, как ИИ может изменить вашу работу.
- Ищите возможности для автоматизации.
- Установите ключевые показатели эффективности (KPI) для улучшения.
- Выберите подходящее ИИ-решение и внедряйте его постепенно.
Ресурсы и помощь
Если вам нужны советы по внедрению ИИ, пишите нам на наш Telegram канал. Также вы можете попробовать ИИ ассистента в продажах, который поможет отвечать на вопросы клиентов и снижать нагрузку на команду.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























