«`html
Преимущества использования Parameter-Efficient Expert Retrieval от Google DeepMind в вашем бизнесе
Практические решения и ценность
Архитектуры трансформера сталкиваются с проблемой роста вычислительных затрат и активационной памяти при увеличении ширины скрытого слоя прямого распространения (FFW). Это ограничение влияет на развертывание крупномасштабных моделей в реальных приложениях, таких как языковое моделирование и обработка естественного языка.
Для решения этой проблемы используются архитектуры Mixture-of-Experts (MoE), которые развертывают разреженно активированные экспертные модули вместо одного плотного слоя FFW. Однако существующие модели MoE сталкиваются с ограничениями в вычислительной эффективности при масштабировании.
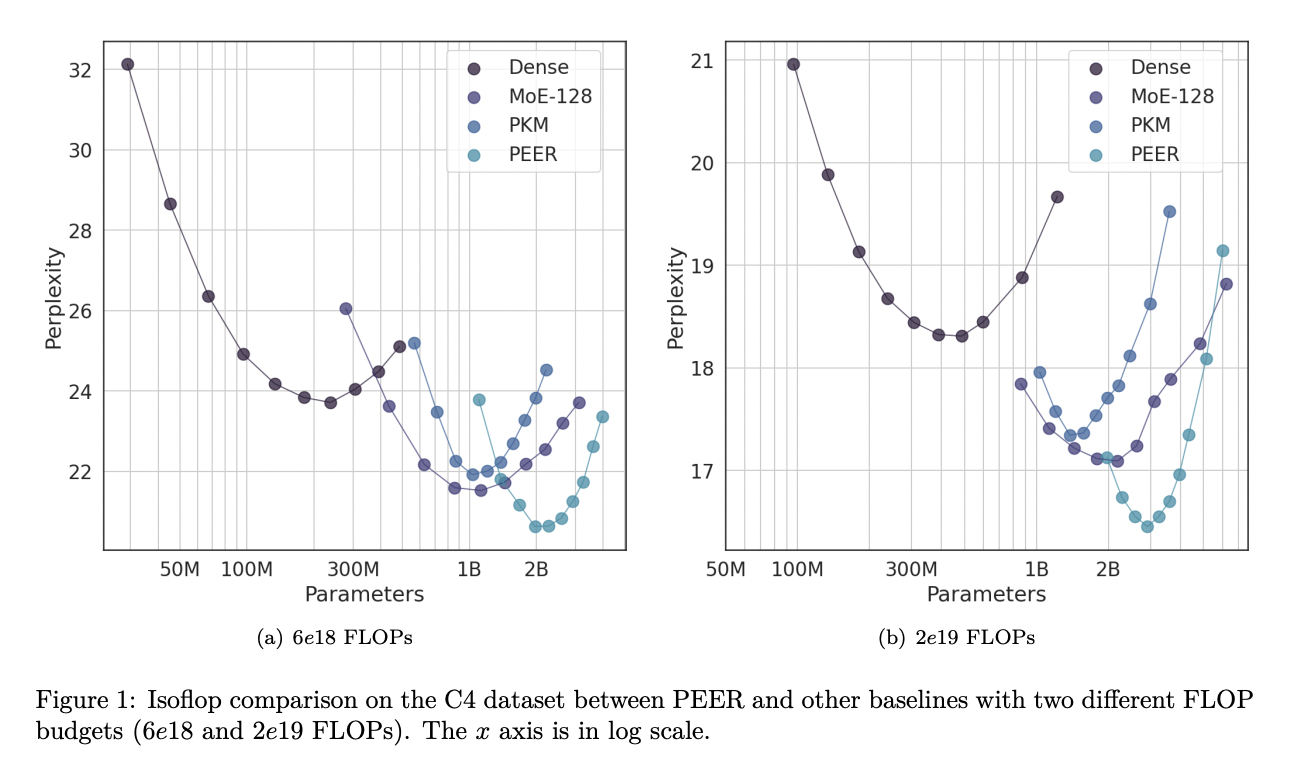
PEER предлагает новый подход, который устраняет ограничения существующих моделей MoE, используя технику Product Key для разреженного извлечения из огромного количества маленьких экспертов. Этот подход повышает производительность моделей MoE и представляет значительное улучшение по сравнению с предыдущими архитектурами.
PEER-слои демонстрируют существенные улучшения в эффективности и производительности для задач языкового моделирования. Результаты экспериментов показывают, что PEER-слои значительно превосходят плотные FFW и грубозернистые MoE по соотношению производительности и вычислительной эффективности.
Этот новый метод представляет собой значительный вклад в исследования в области искусственного интеллекта, обеспечивая более эффективные и мощные языковые модели. PEER может успешно масштабироваться для обработки обширных и непрерывных потоков данных, что делает его многообещающим решением для пожизненного обучения и других сложных приложений искусственного интеллекта.
«`

























