Google DeepMind представляет PaliGemma: универсальную модель VLM для визуально-языкового понимания
Модели визуально-языкового понимания значительно развивались за последние годы, и мы представляем PaliGemma — модель, объединяющую сильные стороны серии моделей PaLI с семейством языковых моделей Gemma. PaliGemma представляет собой уникальный подход, объединяющий передовые техники обработки изображений и языка, что делает его значительным прорывом в мультимодальном искусственном интеллекте.
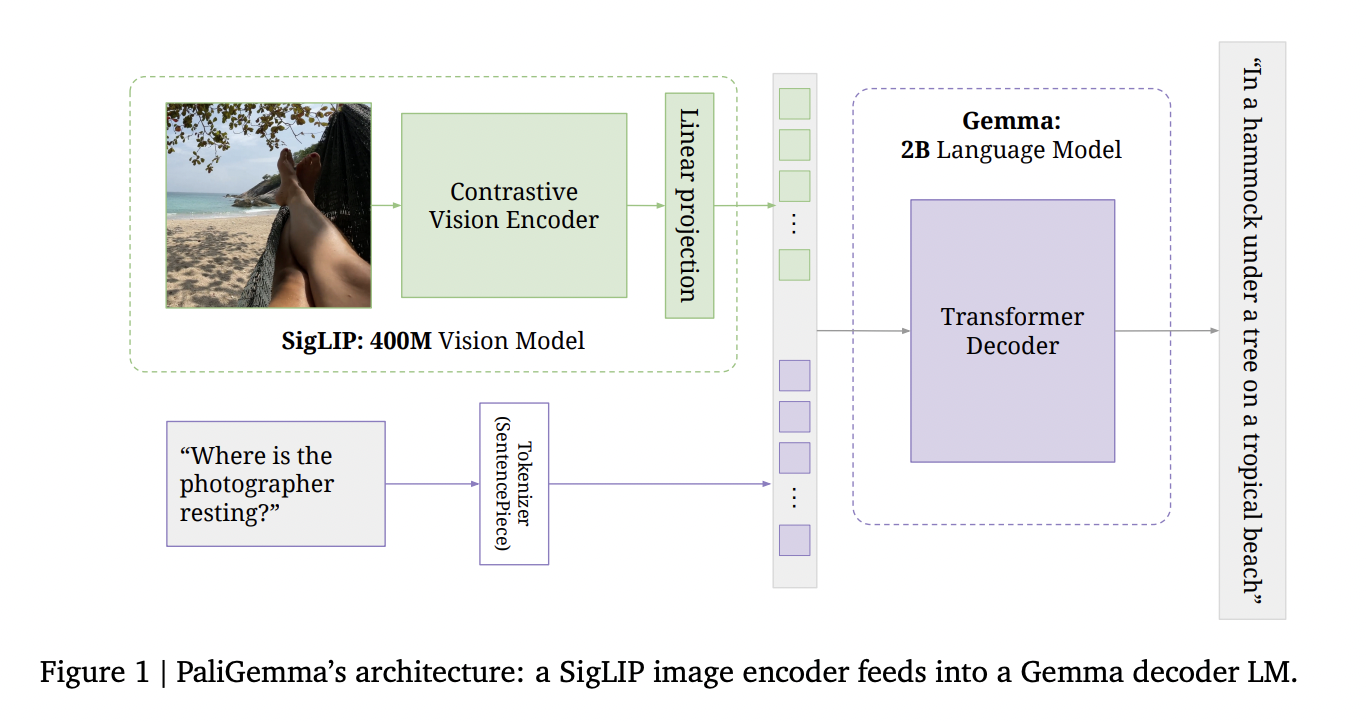
Ключевые компоненты PaliGemma
- Сигнальный кодировщик изображений ViTSo400m
- Декодерная языковая модель Gemma-2B v1.0
- Линейный слой проекции
Эффективная и простая конструкция PaliGemma позволяет обрабатывать различные задачи, включая классификацию изображений, подписывание изображений и визуальный вопросно-ответный интерфейс.
Обучение PaliGemma
Обучение модели включает несколько этапов, начиная с унимодального предобучения отдельных компонентов и заканчивая адаптацией базовой модели к конкретным задачам или сценариям использования.
Результаты исследований
Модель продемонстрировала впечатляющие результаты на широком спектре визуально-языковых задач, включая подписывание и визуальный вопросно-ответный интерфейс.
Заключение
Исследование представляет PaliGemma как устойчивую и компактную открытую модель VLM, которая превосходит современные стандарты в области мультиязыкового обучения передачи знаний. Этот подход стимулирует более эффективное и универсальное использование ИИ в области визуально-языкового понимания.

























