Введение в TGI v3.0 от Hugging Face
Генерация текста является основным компонентом современных технологий обработки естественного языка (NLP). Она позволяет создавать чат-ботов и автоматизированный контент. Однако работа с длинными запросами и динамическими контекстами вызывает серьезные трудности.
Проблемы и ограничения
Существующие системы часто сталкиваются с задержками, неэффективностью памяти и ограничениями в масштабируемости. Это особенно критично для приложений, требующих большого объема контекста, так как узкие места в обработке токенов и использовании памяти препятствуют производительности.
Решение: TGI v3.0
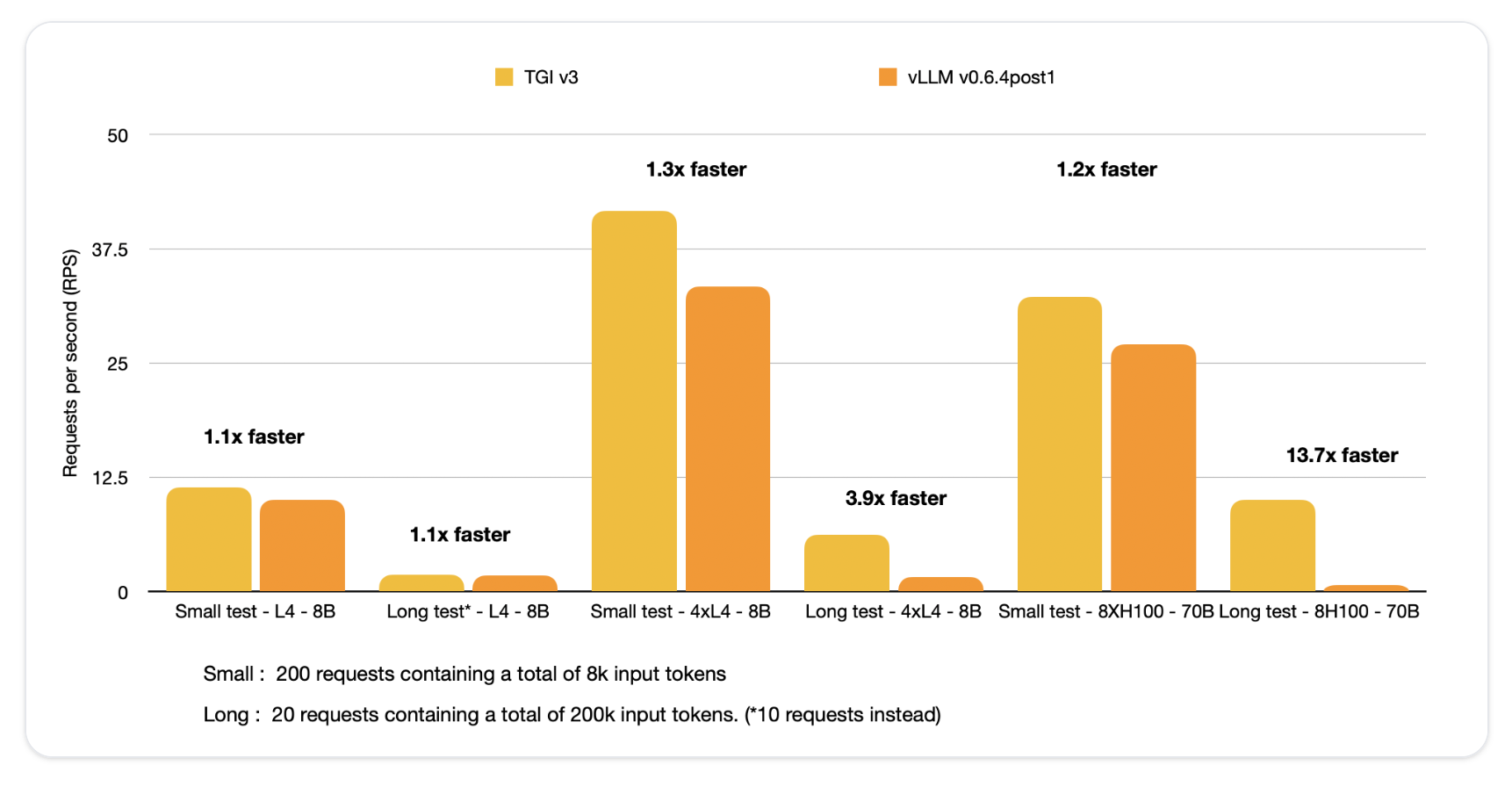
Hugging Face выпустила TGI v3.0, которая предлагает значительные улучшения в эффективности. TGI v3.0 обеспечивает увеличение скорости в 13 раз по сравнению с vLLM при работе с длинными запросами и упрощает развертывание за счет настройки без конфигурации.
Ключевые улучшения
Основные достижения включают тройное увеличение емкости обработки токенов и значительное сокращение объема используемой памяти. Один NVIDIA L4 GPU может обрабатывать 30,000 токенов — в три раза больше, чем vLLM. Оптимизированные структуры данных позволяют быстро извлекать контекст запроса, что существенно снижает время ответа при длительных взаимодействиях.
Технические особенности
TGI v3.0 включает несколько архитектурных усовершенствований. Уменьшая нагрузку на память, система поддерживает большую емкость токенов и динамическое управление длинными запросами. Это особенно полезно для разработчиков в условиях ограниченного оборудования.
Механизм оптимизации запросов позволяет TGI сохранять контекст первоначального разговора, обеспечивая мгновенные ответы на последующие запросы с задержкой всего в 5 микросекунд.
Результаты и преимущества
Тесты производительности показывают, что TGI обрабатывает ответы на запросы, превышающие 200,000 токенов, всего за 2 секунды. Это значительно быстрее, чем 27.5 секунд с vLLM. Оптимизация памяти приносит практическую пользу, особенно при генерации длинного контента или обработки обширной истории разговоров.
Заключение
TGI v3.0 представляет собой значительный шаг вперед в технологии генерации текста. Устраняя основные недостатки в обработке токенов и использовании памяти, она позволяет разработчикам создавать более быстрые и масштабируемые приложения с минимальными усилиями. Модель без конфигурации упрощает доступ к высокопроизводительным решениям в области NLP.
Как использовать ИИ в вашем бизнесе?
Если вы хотите развивать свою компанию с помощью ИИ и оставаться в числе лидеров, следуйте этим шагам:
- Анализируйте, как ИИ может изменить вашу работу.
- Определите, где можно применить автоматизацию для выгоды ваших клиентов.
- Установите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Выбирайте подходящее решение среди множества доступных вариантов ИИ.
- Внедряйте ИИ постепенно, начиная с небольших проектов и анализируя результаты.
Если вам нужны советы по внедрению ИИ, обращайтесь к нам.
Попробуйте ИИ-ассистент в продажах, который помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить ваши процессы
Решения от Flycode.ru помогут вам оптимизировать бизнес-процессы с помощью ИИ.

























