«`html
Мультимодальное обучение: преимущества и практические решения
Мультимодальное обучение — это быстро развивающаяся область, фокусирующаяся на обучении моделей понимать и генерировать контент в различных модальностях, включая текст и изображения. За счет использования обширных наборов данных эти модели могут выстраивать визуальные и текстовые представления в общем пространстве, облегчая задачи, такие как подписывание изображений и поиск текста по изображению. Этот интегрированный подход направлен на улучшение способности модели эффективно обрабатывать разнообразные типы входных данных.
Основные проблемы и решения
Основная проблема, решаемая в данном исследовании, — это неэффективность текущих моделей в управлении только текстовыми и тексто-изображенческими задачами. Обычно существующие модели преуспевают в одной области, тогда как они проявляют слабую производительность в другой, что требует отдельных систем для различных типов информационного поиска. Это увеличивает сложность таких систем и потребности в ресурсах, подчеркивая необходимость более унифицированного подхода.
Текущие методы, такие как Contrastive Language-Image Pre-training (CLIP), выстраивают соответствие между изображениями и текстом через пары изображений и их подписей. Однако эти модели часто сталкиваются с трудностями в выполнении только текстовых задач, поскольку не могут обрабатывать более длинные текстовые входы, что приводит к неоптимальной производительности в сценариях поиска текста и затрудняет обработку задач, требующих эффективного понимания больших объемов текста.
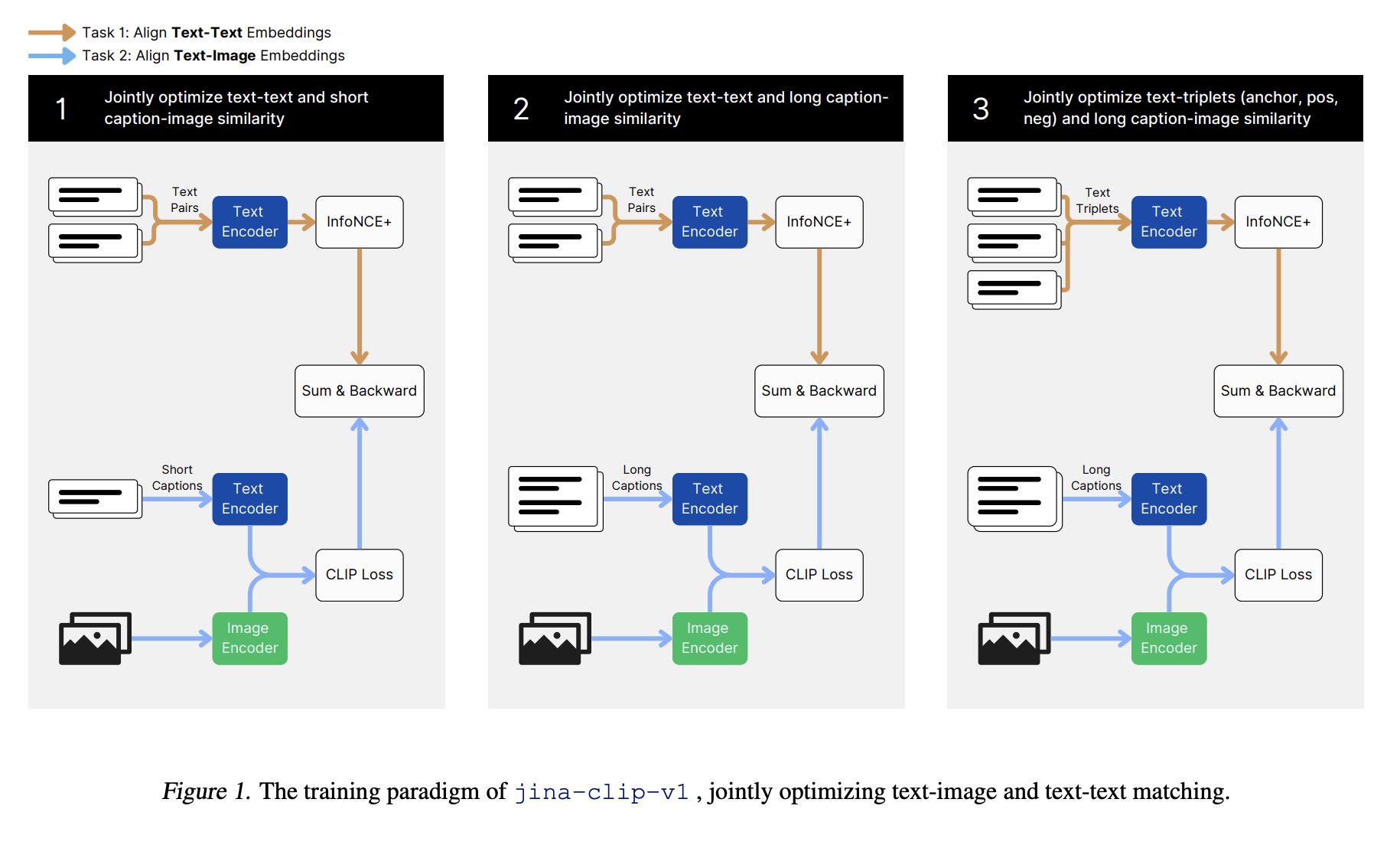
Исследователи Jina AI представили модель Jina-clip-v1, чтобы решить эти проблемы. Эта модель с открытым исходным кодом использует новый мультизадачный контрастный подход к обучению, разработанный для оптимизации соответствия тексто-изображенческих и тексто-текстовых представлений в рамках одной модели. Этот метод направлен на унификацию возможностей эффективной обработки обоих типов задач, сокращая необходимость в отдельных моделях.
Предлагаемый метод обучения для jina-clip-v1 включает в себя трехэтапный процесс. Первый этап сосредотачивается на выстраивании визуальных и текстовых представлений с использованием коротких, созданных людьми подписей, позволяя модели создать основу в мультимодальных задачах. На втором этапе исследователи ввели более длинные синтетические подписи изображений для улучшения производительности модели в задачах поиска текста. Финальный этап включает использование сложных негативов для настройки текстового кодировщика, улучшая его способность различать соответствующие и несоответствующие тексты, сохраняя соответствие текста и изображения.
Оценки производительности демонстрируют, что jina-clip-v1 достигает превосходных результатов в задачах поиска текста и изображений. Например, модель достигла среднего показателя Recall@5 в 85,8% по всем бенчмаркам поиска, превосходя модель CLIP от OpenAI и показывая результаты на уровне EVA-CLIP. Кроме того, в Massive Text Embedding Benchmark (MTEB), включающем восемь задач с участием 58 наборов данных, Jina-clip-v1 близко конкурирует с лучшими моделями только текстовых вложений, достигая среднего показателя 60,12%. Это улучшение по сравнению с другими моделями CLIP составляет приблизительно 15% в общем и 22% в задачах поиска.
Подробная оценка включала несколько этапов обучения. Для обучения тексто-изображенческим данным на первом этапе модель использовала набор данных LAION-400M, содержащий 400 миллионов пар изображений и текста. На этом этапе произошли значительные улучшения в мультимодальной производительности, хотя производительность в обработке текста-текста изначально оказалась недостаточной из-за различий в длине текстов между типами обучающих данных. Последующие этапы включали добавление синтетических данных с более длинными подписями и использование сложных негативов, улучшая производительность в поиске текста и тексто-изображенческих задач.
В заключение, исследование подчеркивает потенциал унифицированных мультимодальных моделей, таких как Jina-clip-v1, в упрощении систем поиска информации путем объединения возможностей понимания текста и изображений в рамках единой структуры. Этот подход предлагает значительные улучшения эффективности для различных приложений за счет снижения потребности в отдельных моделях для различных типов задач, что приводит к потенциальной экономии вычислительных ресурсов и сложности.
Наконец, данное исследование представляет инновационную модель, решающую неэффективность текущих мультимодальных моделей за счет использования мультизадачного контрастного подхода к обучению. Модель jina-clip-v1 преуспевает в задачах поиска текста и изображений, демонстрируя способность эффективно обрабатывать разнообразные входные данные. Этот унифицированный подход представляет собой существенный прогресс в мультимодальном обучении, обещая улучшенную эффективность и производительность для различных приложений.
«`

























