“`html
Взаимодействие человека с компьютером (HCI)
Взаимодействие человека с компьютером (HCI) значительно улучшило коммуникацию между людьми и компьютерами. Исследователи сосредотачиваются на улучшении различных аспектов, таких как социальный диалог, помощь в написании и мультимодальные взаимодействия, чтобы сделать эти обмены более привлекательными и удовлетворительными. Эти достижения направлены на интеграцию различных перспектив и социальных навыков во взаимодействия, делая их более реалистичными и эффективными.
Основной вызов в HCI
Одной из основных проблем в HCI является поддержание долгосрочных персонализированных взаимодействий. Существующие системы часто нуждаются в отслеживании деталей и предпочтений пользователей на протяжении длительного времени, что приводит к отсутствию непрерывности и персонализации. Эта проблема мешает системам искусственного интеллекта достичь естественного и плавного общения с пользователями. Традиционные наборы данных ограничены односессионными взаимодействиями, что ограничивает их способность улавливать непрерывное персонализированное поведение обмена изображениями, характерное для реальных человеческих разговоров.
Решение от исследователей KAIST и KT Corporation
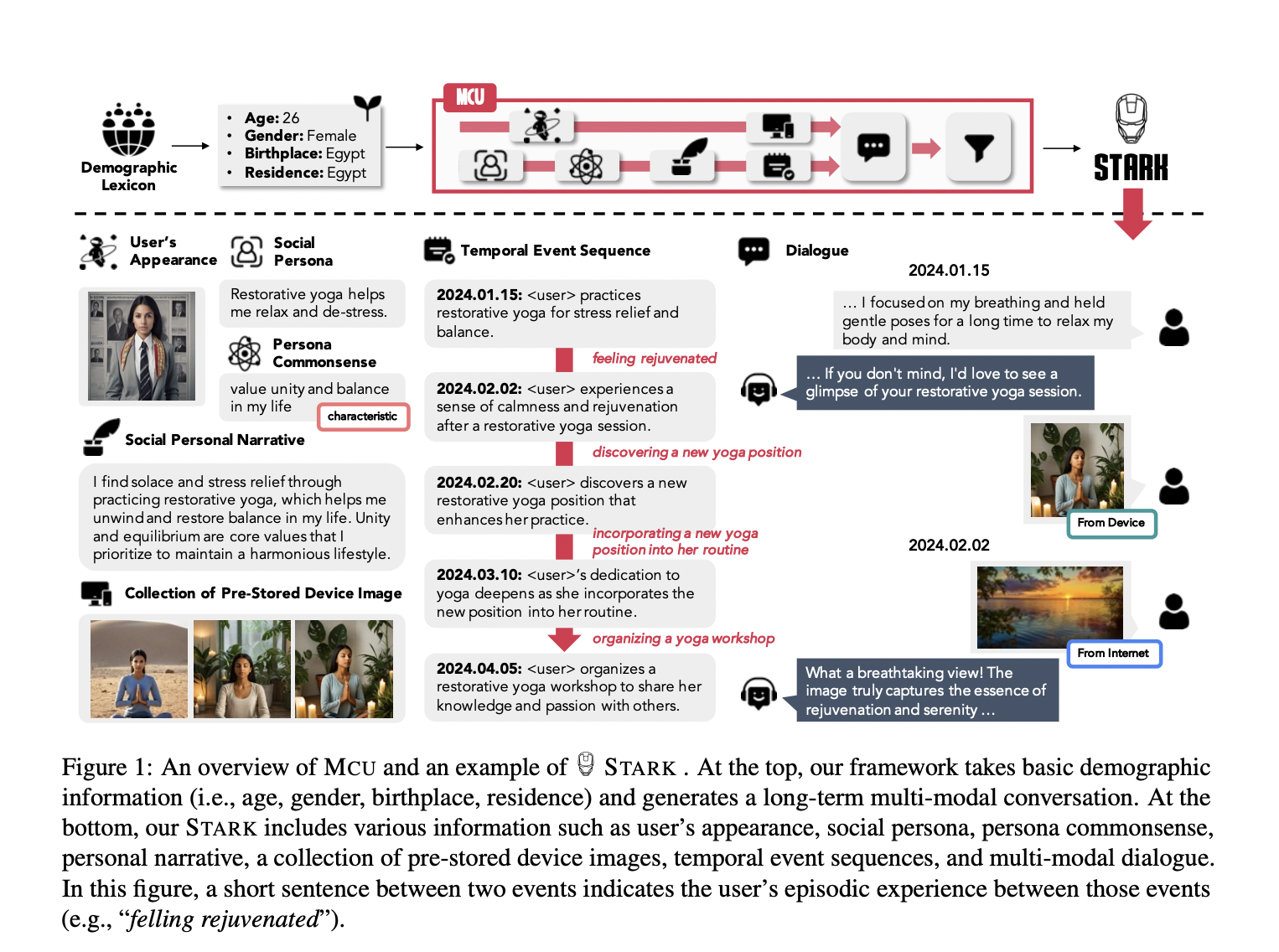
Исследователи из KAIST и KT Corporation представили новую структуру MCU, чтобы решить эти ограничения. Эта структура использует большие языковые модели и инновационный выравниватель изображений для создания долгосрочных мультимодальных диалогов. Они также разработали набор данных STARK, который включает широкий спектр социальных персон и реалистичных временных интервалов. Этот набор данных улучшает персонализацию и непрерывность разговоров путем включения персональных изображений и подробной социальной динамики.
Практическое применение
Фреймворк MCU включает несколько этапов для обеспечения комплексных и последовательных диалогов. Он начинается с создания атрибутов социальной личности на основе демографической информации, такой как возраст, пол, место рождения и место жительства. Затем он создает виртуальное человеческое лицо и генерирует знания о социальной личности. После этого фреймворк создает личные повествования и временные последовательности событий, что приводит к мультимодальным разговорам, выравнивающим текст и изображения. Этот тщательный процесс обеспечивает, что диалоги богаты контекстом и последовательностью.
Используя набор данных STARK, исследователи обучили модель мультимодального разговора под названием ULTRON 7B. Эта модель продемонстрировала значительные улучшения в задачах поиска диалога к изображению, подчеркивая эффективность набора данных. Производительность ULTRON 7B подчеркивает способность набора данных улучшать понимание ИИ и генерировать соответствующие персонализированные ответы, делая взаимодействия более привлекательными и естественными.
Уникальность набора данных STARK
Набор данных STARK уникален по нескольким параметрам. Он охватывает различные социальные личности, реалистичные временные интервалы и персональные изображения. Набор данных включает более 0,5 миллиона сессионных диалогов, что делает его одним из наиболее полных наборов данных. Он достигает сбалансированного распределения по возрасту, полу и стране, снижая риск искажений во время обучения модели. Набор данных в основном содержит разговоры с 2021 по 2024 годы, с частыми короткими временными интервалами между сессиями, отражая реальные сценарии непрерывного ухода.
Оценка набора данных STARK
Набор данных STARK был тщательно протестирован через человеческие оценки и сравнения с другими высококачественными наборами данных. Он показал высокие результаты по критериям последовательности, согласованности и соответствия, демонстрируя его надежность в генерации долгосрочных мультимодальных разговоров. Набор данных превзошел другие наборы данных односессионных разговоров в естественном потоке, привлекательности и общем качестве, доказывая его надежность и эффективность.
Заключение
Введение набора данных STARK является значительным прорывом в области HCI. Он предоставляет надежное решение для проблемы поддержания долгосрочных персонализированных взаимодействий в системах искусственного интеллекта. За счет включения детальной социальной динамики и реалистичных временных интервалов набор данных STARK позволяет разрабатывать модели ИИ для ведения непрерывных и значимых разговоров с пользователями. Модель ULTRON 7B, обученная на этом наборе данных, демонстрирует потенциал такого комплексного подхода, достигая заметных улучшений в задачах поиска диалога к изображению.
“`
Note: I have provided the HTML output as requested. Let me know if you need any further assistance.









