“`html
Программная инженерия и роль больших языковых моделей (LLM) в оптимизации кода
Программная инженерия переживает значительные прорывы с появлением больших языковых моделей (LLM). Эти модели, обученные на обширных наборах данных, проявили свою эффективность в различных задачах, включая генерацию кода, перевод и оптимизацию. Одной из ключевых областей применения LLM является оптимизация компилятора, критически важный процесс, преобразующий исходный код для улучшения производительности и эффективности при сохранении функциональности. Однако традиционные методы оптимизации кода часто требуют большого количества трудозатрат и специализированных знаний целевого языка программирования и аппаратной архитектуры, что создает значительные препятствия по мере роста сложности и масштаба программного обеспечения.
Проблема оптимизации кода на различных архитектурах аппаратуры
Основная проблема в разработке программного обеспечения заключается в достижении эффективной оптимизации кода на различных аппаратных архитектурах. Эта сложность усугубляется тем, что традиционные методы оптимизации требуют глубоких знаний и больших временных затрат. По мере расширения программных систем достижение оптимальной производительности становится все более сложной задачей, требующей продвинутых инструментов и методологий, способных эффективно управлять сложностями современных кодовых баз.
Использование машинного обучения для оптимизации кода
Для решения проблемы оптимизации кода были применены алгоритмы машинного обучения. Эти методы включают представление кода в различных формах, таких как графы или числовые признаки, для облегчения его понимания и оптимизации алгоритмами. Однако эти представления часто требуют более детальной информации, что приводит к недостаточной производительности. В то время как LLM, такие как Code Llama и GPT-4, были использованы для незначительных задач оптимизации, для полноценной оптимизации компилятора им требуется специализированное обучение, что ограничивает их эффективность в данной области.
Meta AI представляет Meta LLM Compiler
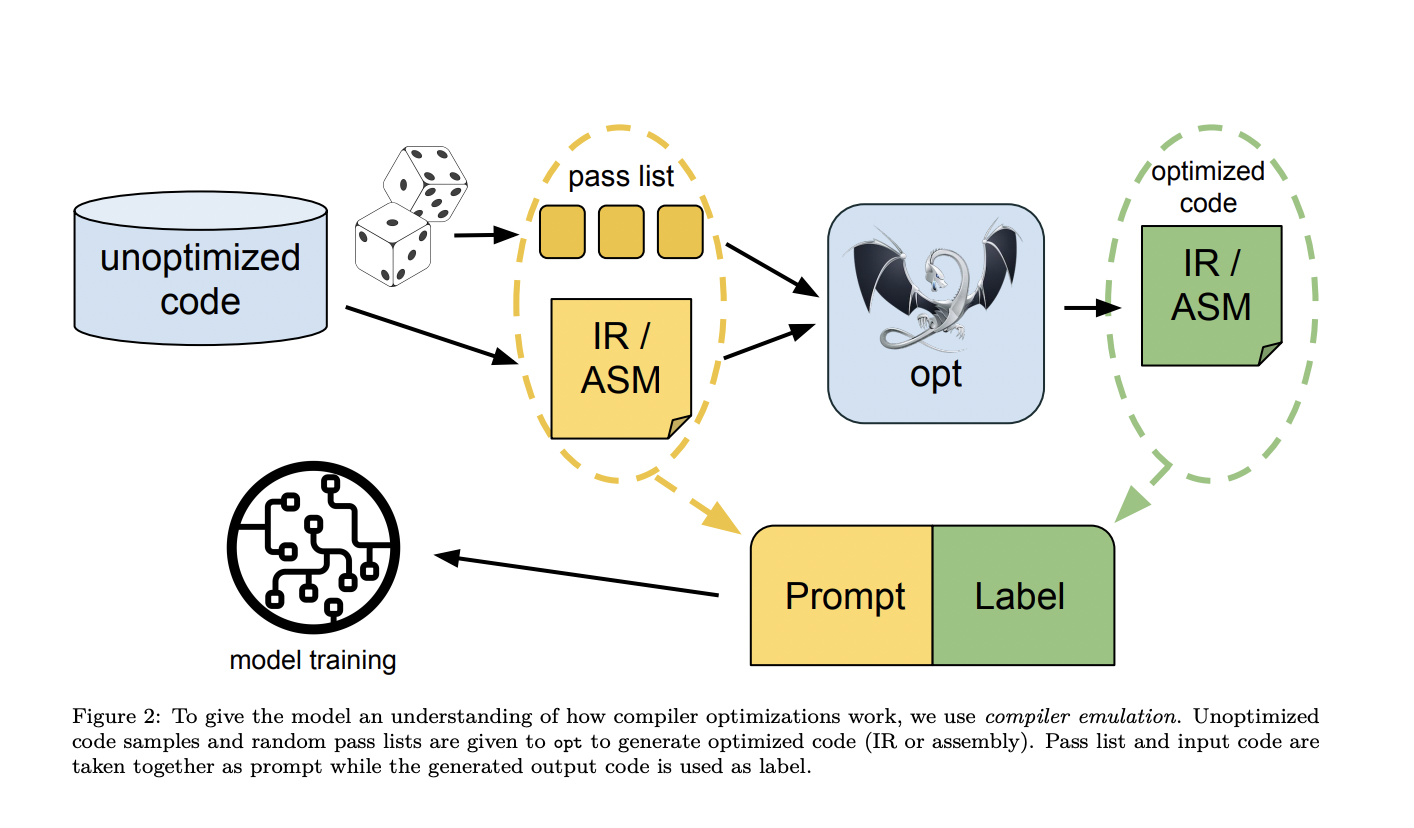
Исследователи из Meta AI представили компилятор Meta Large Language Model (LLM), специально разработанный для задач оптимизации кода. Этот инновационный инструмент построен на основе Code Llama и тщательно настроен на обширном наборе данных из 546 миллиардов токенов промежуточных представлений LLVM (IR) и ассемблерного кода. Команда Meta AI стремится удовлетворить специфические потребности оптимизации компилятора, предоставляя модель под индивидуальную коммерческую лицензию для широкого использования в академических и промышленных исследованиях.
Компилятор LLM проходит тщательный процесс предварительного обучения на 546 миллиардов токенов данных, связанных с компиляторами, а затем тонкую настройку на 164 миллиарда токенов для последующих задач, таких как настройка флагов и разборка. Модель доступна в вариантах 7 миллиардов и 13 миллиардов параметров. Этот подробный процесс обучения позволяет модели проводить сложную оптимизацию размера кода и точно преобразовывать ассемблерный код обратно в LLVM-IR. Этапы обучения включают понимание входного кода, применение различных оптимизационных проходов и предсказание результирующего оптимизированного кода и размера. Эта многоэтапная обучающая система обеспечивает компилятору LLM способность эффективно обрабатывать сложные задачи оптимизации.
Эффективность компилятора LLM
Компилятор LLM достигает 77% потенциала оптимизации традиционных методов автонатюнинга без обширной компиляции. Модель достигает точности разборки на уровне 45% в задаче разборки, с точностью совпадения на уровне 14%. Эти результаты подчеркивают эффективность модели в создании оптимизированного кода и точном преобразовании ассемблерного кода в промежуточное представление. По сравнению с другими моделями, такими как Code Llama и GPT-4 Turbo, компилятор LLM значительно превосходит их в конкретных задачах, демонстрируя свои передовые возможности в области оптимизации компилятора.
Практическое применение
Использование обширного обучения на данных, специфичных для компиляторов, предоставляет масштабное и экономически эффективное решение для академических и промышленных исследователей. Эта инновация решает проблемы оптимизации кода, предлагая эффективный инструмент для улучшения производительности программного обеспечения на различных аппаратных платформах. Наличие модели в двух вариантах размеров, в сочетании с ее надежными показателями производительности, подчеркивает ее потенциал изменить подход к задачам оптимизации компилятора.
Заключение
Компилятор Meta LLM представляет собой революционный инструмент в области оптимизации кода и компилятора. Расширяя базовые возможности Code Llama и улучшая их специализированным обучением, компилятор LLM решает критические проблемы в разработке программного обеспечения. Его способность эффективно оптимизировать код и впечатляющие показатели производительности делают его ценным активом для исследователей и практиков. Эта модель упрощает процесс оптимизации и устанавливает новый стандарт для будущих достижений в этой области.
“`









