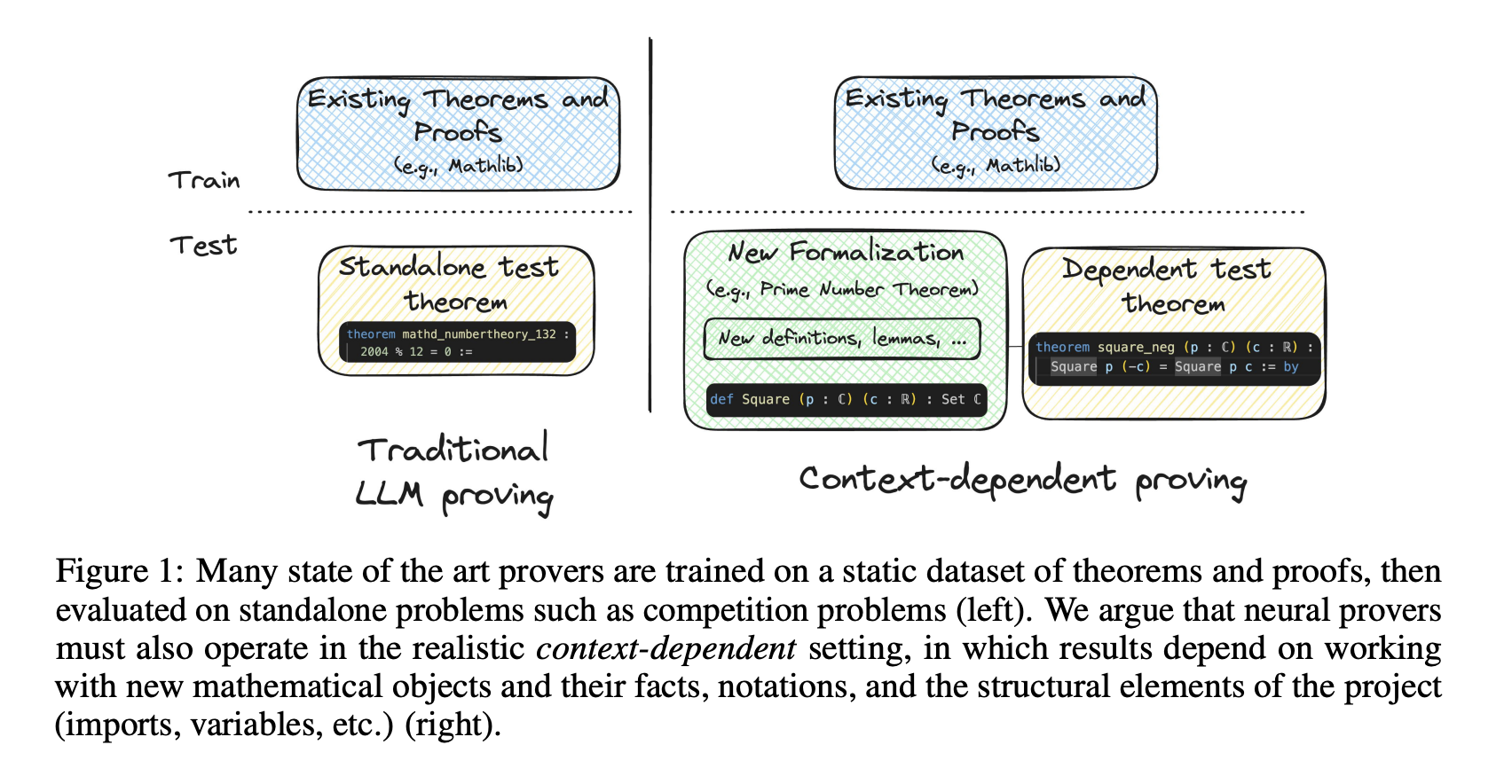
МиниCTX: Прогресс в Доказательстве Теорем с Учетом Контекста
Формальное доказательство теорем стало важным критерием для оценки возможностей рассуждения больших языковых моделей (LLM). Эти модели могут помочь математикам, но существует проблема с применением их в реальных условиях.
Проблемы Современных Моделей
Существующие методы оценки не всегда отражают сложность математического рассуждения. Это ограничивает практическое применение LLM в доказательствах теорем. Необходимы более продвинутые методы оценки, которые смогут учитывать все аспекты математического доказательства.
Подходы к Улучшению Моделей
Разработаны различные методы для улучшения возможностей моделей в доказательстве теорем. Например:
- Предсказание следующего шага: модели генерируют следующий шаг доказательства на основе текущего состояния.
- Учет предпосылок: использование релевантных математических предпосылок в процессе генерации.
- Контекст файлов: дообучение моделей с учетом контекста файлов для генерации полных доказательств.
Решение от Carnegie Mellon University
Исследователи представили систему MiniCTX, которая улучшает оценку возможностей доказательства теорем в LLM. Она учитывает множество контекстуальных элементов, таких как:
- предпосылки
- предыдущие доказательства
- замечания и нотации
- структурные компоненты
Эта система использует NTP-TOOLKIT для автоматического извлечения релевантных теорем и контекстов, что обеспечивает актуальность данных.
Структура MiniCTX
Система основана на наборе данных из 376 теорем, включая известные математические проекты. Каждый элемент включает:
- формулировку теоремы
- полное содержание предыдущих файлов
- подробные метаданные
Это позволяет точно восстанавливать контекст и получать доступ к информации как внутри файла, так и между файлами.
Результаты Экспериментов
Эксперименты показали значительное улучшение производительности при использовании методов, зависящих от контекста. Например, модель, обученная на контексте файлов, достигла 35.94% успеха, в то время как модель, полагающаяся только на состояния доказательства, показала 19.53%.
Будущие Направления Развития
Исследования выявили важные области для дальнейшего развития:
- Улучшение обработки длинных контекстов.
- Интеграция контекста на уровне репозитория.
- Повышение производительности на сложных доказательствах.
Как Использовать ИИ для Вашего Бизнеса
Если вы хотите развивать свою компанию с помощью ИИ, рассмотрите внедрение решений, подобных MiniCTX. Проанализируйте, как ИИ может изменить вашу работу и определить ключевые показатели эффективности (KPI), которые вы хотите улучшить.
Шаги по Внедрению ИИ
- Подберите подходящее решение.
- Начните с небольшого проекта и анализируйте результаты.
- Расширяйте автоматизацию на основе полученных данных.
Получите Помощь
Если вам нужны советы по внедрению ИИ, пишите нам. Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.









