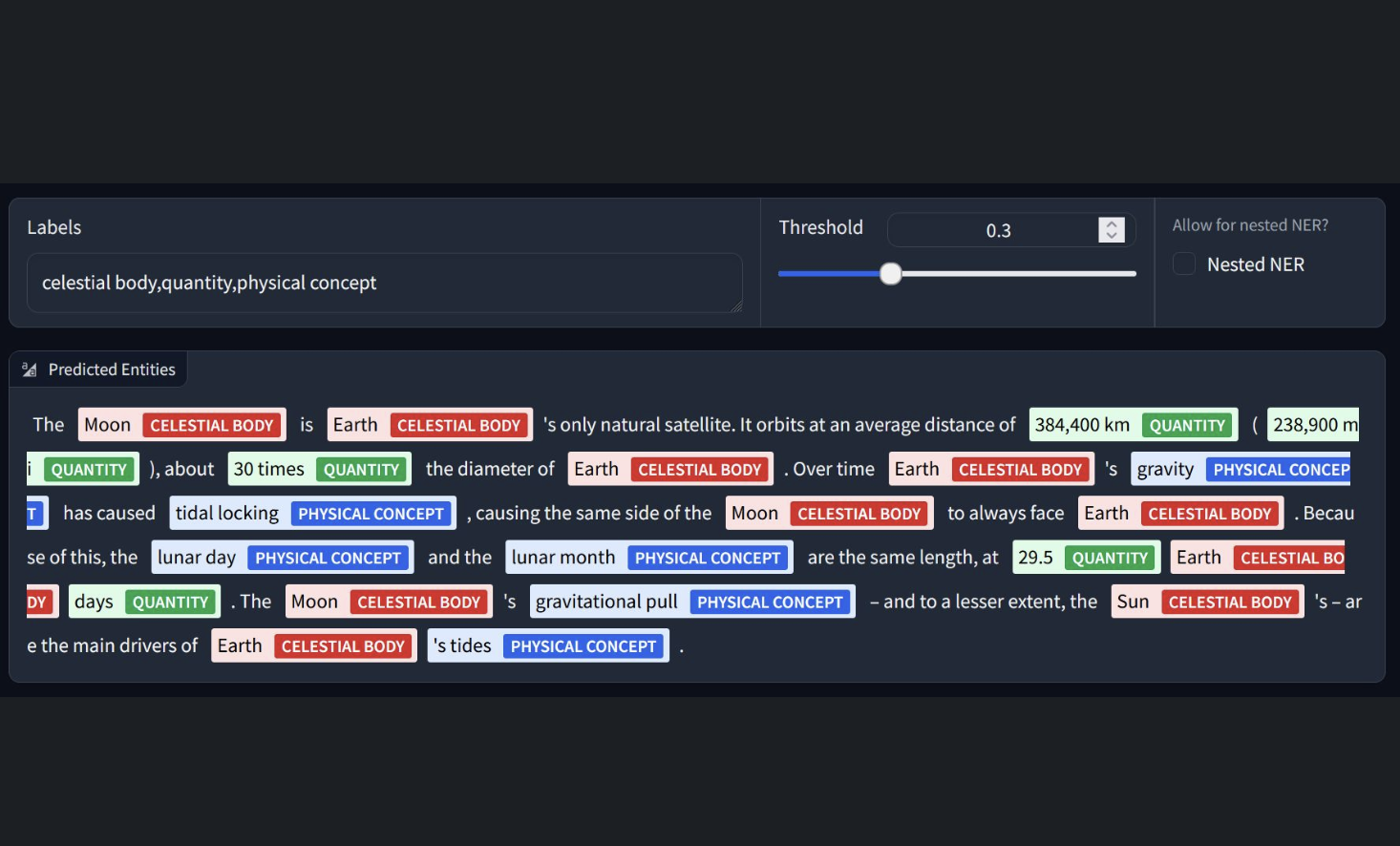
Важность распознавания именованных сущностей (NER) в обработке естественного языка
Распознавание именованных сущностей (NER) играет важную роль в обработке естественного языка и находит применение в медицинском кодировании, финансовом анализе и разборе юридических документов. Пользовательские модели обычно создаются с использованием предварительно обученных трансформерных кодировщиков, предварительно обученных на задачах самообучения, таких как маскированное моделирование языка (MLM). Однако в последние годы наблюдается рост больших языковых моделей (LLM), таких как GPT-3 и GPT-4, которые могут решать задачи NER через хорошо разработанные подсказки, но представляют сложности из-за высоких затрат на вывод и потенциальных проблем с конфиденциальностью.
Практические решения и ценность
Команда NuMind предлагает подход, который предполагает использование LLM для минимизации аннотаций человека при создании пользовательской модели. Вместо использования LLM для аннотации набора данных одной области для конкретной задачи NER, идея заключается в использовании LLM для аннотации разнообразного, мультидоменного набора данных, охватывающего различные проблемы NER. Впоследствии более маленькая базовая модель, такая как BERT, дополнительно предварительно обучается на этом аннотированном наборе данных. Эта предварительно обученная модель затем может быть донастроена для любой последующей задачи NER.
Три модели NER, представленные командой NuMind
1. NuNER Zero: Компактная модель нулевого сброса, обученная на наборе данных NuNER v2.0, которая является ведущей моделью нулевого сброса NER, похваставшейся улучшением F1-оценки на уровне токенов на 3,1% по сравнению с GLiNER-large-v2.1 на бенчмарке GLiNER.
2. NuNER Zero 4k: Версия NuNER Zero с длинным контекстом (4k токенов), которая в целом менее производительна, чем NuNER Zero, но может превзойти NuNER Zero в приложениях, где размер контекста имеет значение.
3. NuNER Zero-span: Версия предсказания диапазона NuNER Zero, которая показывает немного лучшую производительность, чем NuNER Zero, но не может обнаруживать сущности, превышающие 12 токенов.
Основные характеристики моделей
— NuNER Zero: Удобна для модернизации размера токена.
— NuNER Zero 4K: Вариация NuNER, работает лучше в сценариях, где важен размер контекста.
— NuNER Zero-span: Версия предсказания диапазона NuNER Zero, неудобна для сущностей, превышающих 12 токенов.
Заключение
NER играет важную роль в обработке естественного языка, и хотя создание пользовательских моделей обычно зависит от трансформерных кодировщиков, обученных с использованием MLM, появление LLM, таких как GPT-3 и GPT-4, представляет определенные вызовы из-за высоких затрат на вывод. Команда NuMind предлагает подход, использующий LLM для уменьшения аннотаций человека путем аннотации мультидоменного набора данных. Они представляют три модели NER: NuNER Zero, компактная модель нулевого сброса; NuNER Zero 4k, акцентирующая внимание на более длинном контексте; и NuNER Zero-span, приоритизирующая предсказание диапазона с незначительным улучшением производительности, но ограниченная сущностями до 12 токенов.

























