“`html
NuMind представляет NuExtract: легкая модель текст-в-JSON LLM, специализированная на задаче структурированного извлечения
NuExtract – это передовая модель текст-в-JSON, которая представляет собой значительный прорыв в извлечении структурированных данных из текста. Эта модель призвана преобразовывать неструктурированный текст в структурированные данные с высокой эффективностью. Инновационный дизайн и методики обучения, используемые в NuExtract, позиционируют его как превосходную альтернативу существующим моделям, обеспечивая высокую производительность и экономичность.
Практические решения и ценность
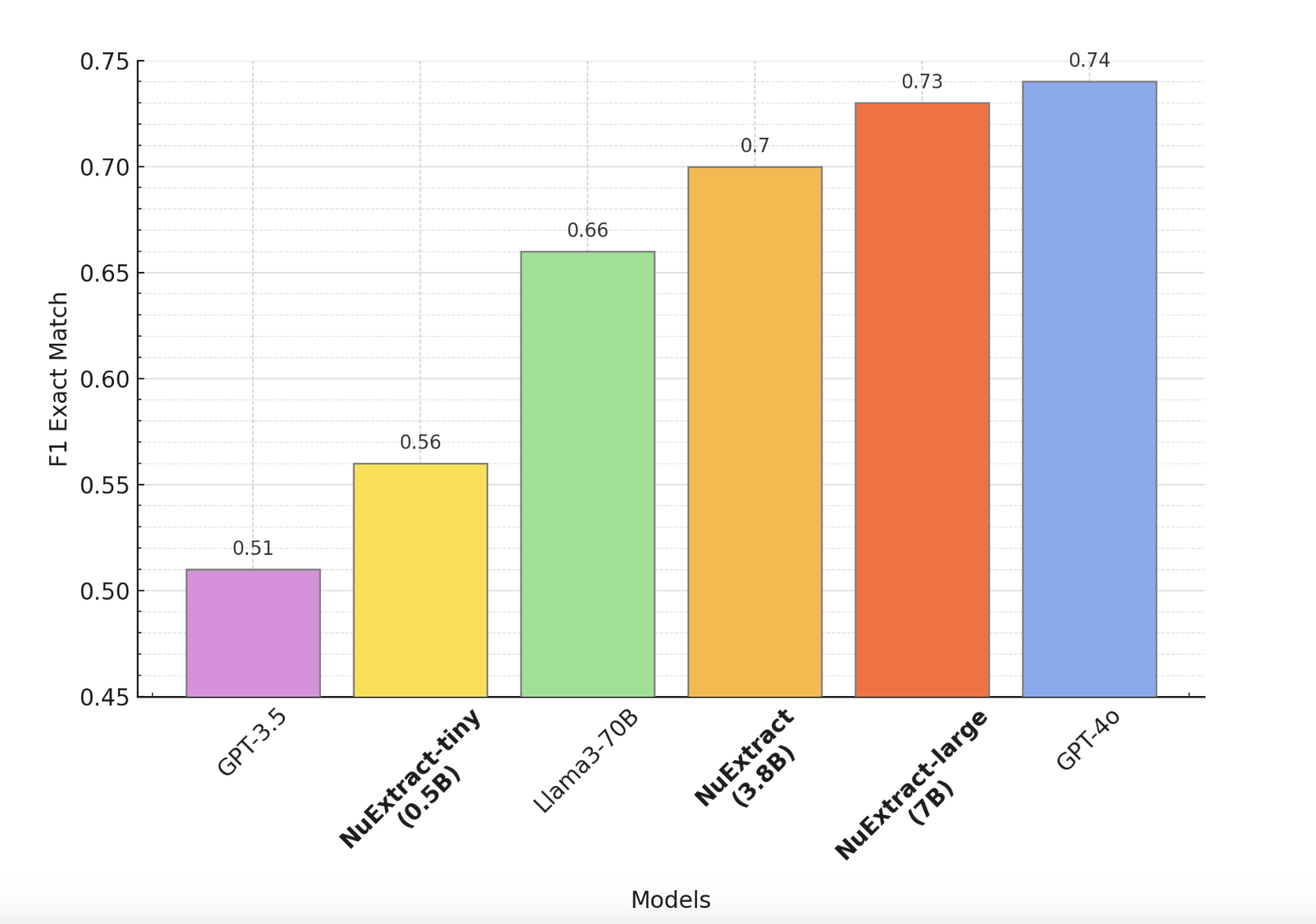
NuExtract разработан для эффективной работы с моделями от 0,5 миллиарда до 7 миллиардов параметров, достигая сходных или превосходящих возможностей извлечения по сравнению с более крупными и популярными языковыми моделями (LLM). Эта эффективность достигается путем создания трех отдельных моделей в семействе NuExtract: NuExtract-tiny, NuExtract и NuExtract-large. Эти модели продемонстрировали выдающуюся производительность в различных задачах извлечения, часто превосходя значительно более крупные LLM.
НуExtract доступен в трех обученных версиях:
- NuExtract-tiny (0,5B): Легкая модель, идеально подходящая для приложений, требующих эффективной производительности при минимальных вычислительных ресурсах.
- NuExtract (3,8B): Модель, сбалансированная по размеру и производительности, подходящая для более требовательных задач извлечения.
- NuExtract-large (7B): Самая мощная версия, предназначенная для самых сложных и интенсивных задач извлечения.
Основное преимущество NuExtract заключается в его способности обрабатывать нулевые и точные сценарии извлечения. Модель может извлекать информацию исключительно на основе заранее определенного шаблона или схемы в нулевом режиме без необходимости тренировочных данных, что особенно ценно для приложений, где создание больших аннотированных наборов данных непрактично.
Для обучения NuExtract разработчики использовали новый подход: они использовали большой и разнообразный корпус текста из набора данных C4, который был аннотирован с использованием современной LLM с тщательно разработанными подсказками. Эти синтетические данные затем использовались для настройки компактной общей модели, что обеспечило высокоспециализированную модель для конкретной задачи.
В заключение, NuExtract от NuMind представляет собой значительный прорыв в извлечении структурированных данных из текста. Его инновационный дизайн, эффективная методология обучения и впечатляющая производительность в различных задачах делают его ценным инструментом для преобразования неструктурированного текста в структурированные данные.
“`


























