Qwen2-Audio: Революционная аудио-языковая модель, преодолевающая сложные аудио-вызовы с беспрецедентной точностью и универсальными возможностями взаимодействия
Аудио, как средство, имеет огромный потенциал для передачи сложной информации, поэтому разработка систем, способных точно интерпретировать и реагировать на аудиовходы, является важной. Создание моделей, способных понимать широкий спектр звуков, от устной речи до окружающего шума, и использовать это понимание для облегчения более естественного взаимодействия между людьми и машинами, является целью этой области. Эти достижения ключевы для продвижения границ искусственного общего интеллекта (AGI), где машины не только обрабатывают аудио, но и извлекают из него смысл и контекст.
Основные преимущества Qwen2-Audio:
- Простота предварительной обработки
- Расширение объема данных
- Интеграция передовой архитектуры
Одним из основных вызовов в этой области является разработка систем, способных обрабатывать разнообразные аудиосигналы в реальных сценариях. Традиционные модели часто не справляются с распознаванием и реагированием на сложные аудиовходы, такие как перекрывающиеся звуки, многоголосные среды и смешанные аудиоформаты. Проблема усугубляется, когда от этих систем ожидается работа без обширной настройки под конкретную задачу. Это ограничение подтолкнуло исследователей к изучению новых методологий, которые могли бы лучше оснастить модели для работы с непредсказуемостью и сложностью аудиоданных реального мира, тем самым улучшая их способность следовать инструкциям и точно реагировать в различных контекстах.
Исторически аудио-языковые модели полагались на иерархические системы тегирования и сложные процессы предварительной обученности. Эти модели, такие как Whisper и SpeechT5, были инструментальны в продвижении области, но требуют значительной настройки для успешной работы над конкретными задачами. Например, Whisper-large-v3 известен своими возможностями нулевой оценки на определенных наборах данных, но испытывает трудности с задачами, требующими понимания за пределами простого распознавания речи. Несмотря на улучшения, эти модели показали ограничения в сценариях, требующих тонкой интерпретации мультимодальных аудиоданных, таких как одновременная речь, музыка и окружающие звуки.
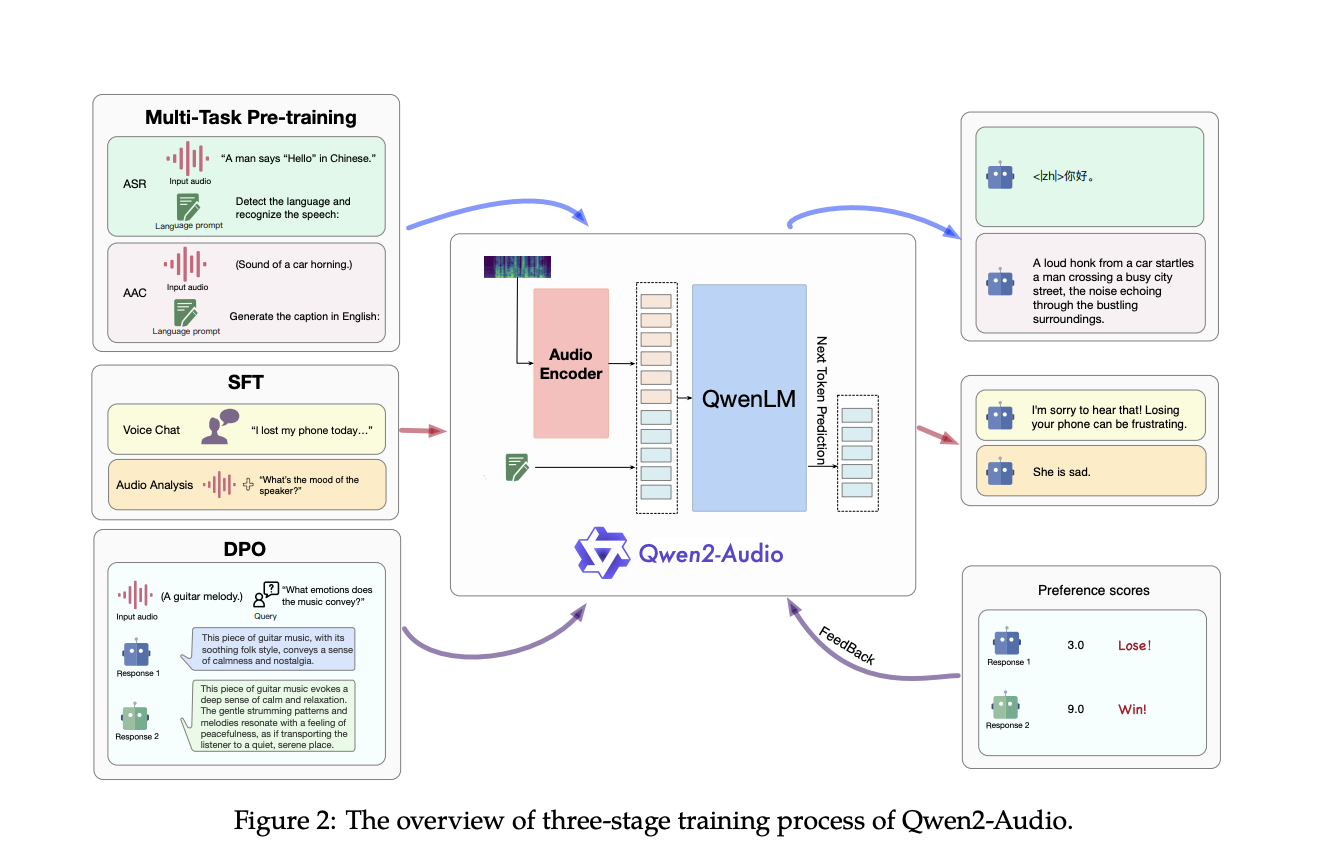
Исследователи команды Qwen в Alibaba Group представили Qwen2-Audio, передовую масштабную аудио-языковую модель, разработанную для обработки и реагирования на сложные аудиосигналы без необходимости обширной настройки под конкретную задачу. Qwen2-Audio отличается упрощением процесса предварительного обучения с использованием естественных языковых подсказок вместо иерархических тегов, значительным расширением объема данных модели и улучшением ее способности следовать инструкциям. Модель работает в двух основных режимах: Voice Chat и Audio Analysis, позволяя ей участвовать в свободном взаимодействии голосом или анализировать различные типы аудиоданных в соответствии с инструкциями пользователя. Двухрежимная функциональность обеспечивает плавное переключение Qwen2-Audio между задачами без отдельных системных подсказок.
Архитектура Qwen2-Audio интегрирует сложный аудио-кодер, инициализированный на основе модели Whisper-large-v3, с моделью большого языка Qwen-7B в качестве ее основной составляющей. Процесс обучения включает преобразование сырых аудио-волн в 128-канальные мел-спектрограммы, которые затем обрабатываются с использованием окна размером 25 мс и шага 10 мс. Полученные данные проходят через слой пулинга, сокращая длину аудиопредставления и обеспечивая, что каждый кадр соответствует примерно 40 мс исходного аудиосигнала. С 8,2 миллиардами параметров Qwen2-Audio способна обрабатывать различные аудиовходы, от простой речи до сложных, мультимодальных аудио-сред.
Результаты оценки производительности показывают, что Qwen2-Audio превосходит предыдущие модели в различных показателях, превзойдя их в задачах, таких как автоматическое распознавание речи (ASR), перевод речи в текст (S2TT) и распознавание эмоций речи (SER). Модель достигла уровня ошибок слов (WER) 1,6% на тестовом наборе данных Librispeech test-clean и 3,6% на тестовом наборе данных test-other, значительно улучшив показатели предыдущих моделей, таких как Whisper-large-v3. В задаче перевода речи в текст Qwen2-Audio превзошла базовые модели в семи направлениях перевода, достигнув BLEU-оценки 45,2 в направлении en-de и 24,4 в направлении zh-en. Кроме того, в задаче классификации вокального звука (VSC) Qwen2-Audio достигла точности 93,92%, демонстрируя свою надежную производительность в различных аудиозадачах.
В заключение, Qwen2-Audio, упрощая процесс предварительной обработки, расширяя объем данных и интегрируя передовую архитектуру, модель преодолевает ограничения своих предшественников и устанавливает новый стандарт для систем взаимодействия с аудио. Ее способность хорошо выполнять различные задачи без необходимости обширной настройки под конкретную задачу подчеркивает ее потенциал изменить способы обработки и взаимодействия машин с аудиосигналами.

























