SepLLM: Практичное решение для эффективного использования разреженного внимания в больших языковых моделях
Большие языковые модели (БЯМ) демонстрируют впечатляющие возможности в обработке естественного языка, однако их эффективность часто страдает от сложности механизма самовнимания. Это особенно актуально для длинных последовательностей, где требования к вычислениям и памяти значительно возрастают.
Предложенное решение: SepLLM
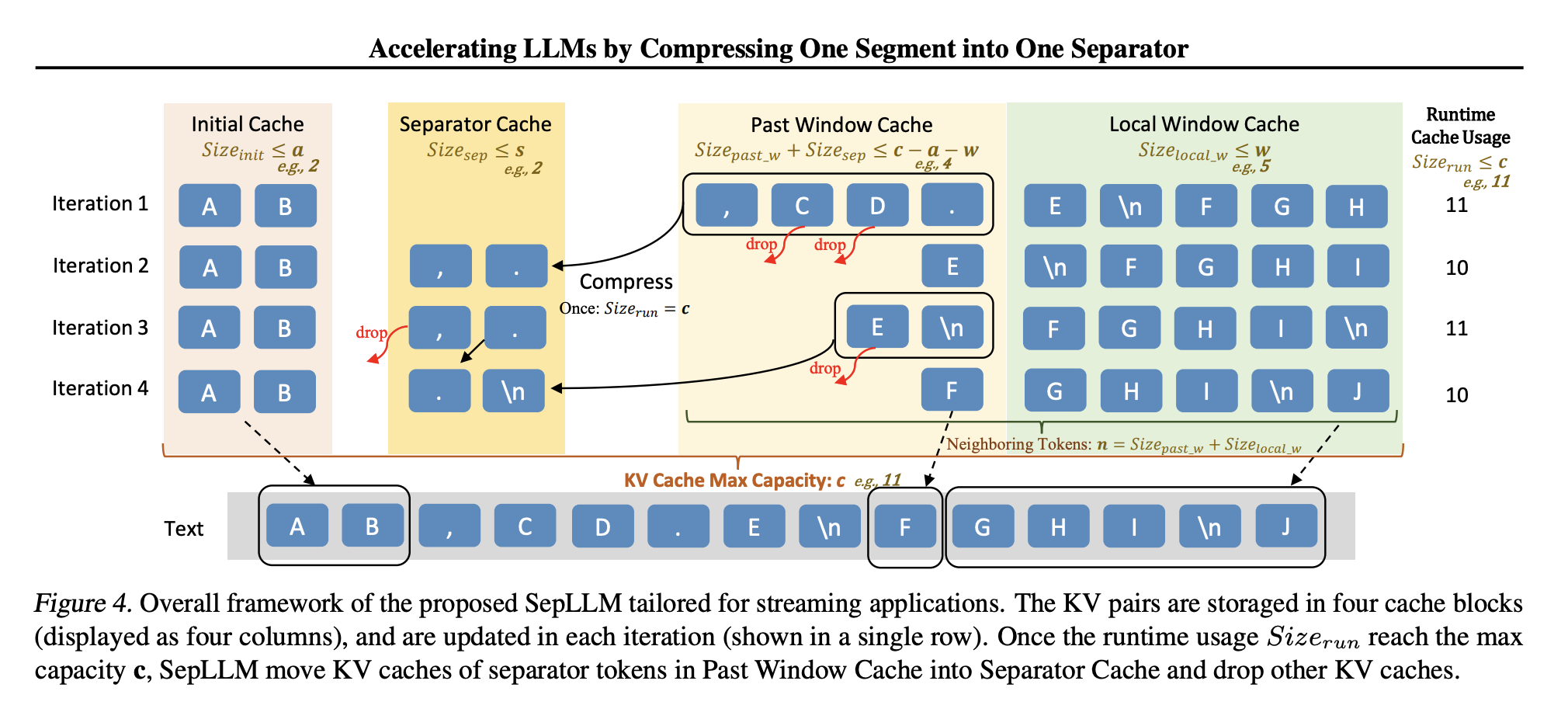
Исследователи из Huawei Noah’s Ark Lab, Гонконгского университета, KAUST и Института Макса Планка предложили SepLLM — механизм разреженного внимания, который упрощает вычисления. SepLLM фокусируется на трех типах токенов:
- Начальные токены: Первые токены в последовательности, важные для понимания контекста.
- Соседние токены: Токены, находящиеся рядом с текущим, обеспечивающие локальную согласованность.
- Токены-разделители: Часто встречающиеся токены, такие как запятые и точки, которые обобщают информацию сегмента.
Используя эти токены, SepLLM снижает вычислительные нагрузки, сохраняя при этом эффективность модели.
Преимущества SepLLM
- Обработка длинного текста: SepLLM обрабатывает последовательности длиной более четырех миллионов токенов, что полезно для таких задач, как суммирование документов и длинные беседы.
- Улучшение эффективности вывода и использования памяти: Механизм компрессии на основе токенов-разделителей ускоряет вывод и снижает использование памяти, например, на тесте GSM8K-CoT использование кэша KV сократилось на 50%.
- Универсальное развертывание: SepLLM можно адаптировать под различные сценарии развертывания, включая интеграцию с предварительно обученными моделями и обучение с нуля.
Экспериментальные результаты
Эффективность SepLLM была подтверждена тестированием:
- В условиях без обучения: SepLLM соответствовал производительности моделей с полным вниманием, снизив использование кэша KV до 47%.
- При обучении с нуля: SepLLM демонстрировал более быструю сходимость и улучшенную точность задач.
- Впоследствии: SepLLM эффективно адаптировался к предварительно обученным моделям через дообучение.
- В потоковых приложениях: SepLLM показал более низкую перплексию и более быстрое время вывода, чем альтернативные модели.
Резюме
SepLLM решает актуальные проблемы масштабируемости и эффективности БЯМ, фокусируясь на ключевых токенах. Его разреженный механизм внимания обеспечивает баланс между вычислительными требованиями и производительностью, что делает его привлекательным решением для современных задач НЛП.
Внедрение решений ИИ в вашу компанию
Если вы хотите, чтобы ваша компания использовала ИИ для достижения успеха, рассмотрите следующие шаги:
- Анализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Выберите подходящее решение для вашей компании и начните с небольшого проекта.
- Постепенно расширяйте автоматизацию на основе полученных данных.
Если вам нужны советы по внедрению ИИ, свяжитесь с нами. Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























