«`html
Искусственный интеллект в области языковых моделей
Искусственный интеллект постоянно развивается, сосредотачиваясь на оптимизации алгоритмов для улучшения производительности и эффективности больших языковых моделей (LLM). Одной из основных задач в этой области является обучение с подкреплением на основе обратной связи от людей (RLHF), направленное на выравнивание моделей ИИ с человеческими ценностями и намерениями, чтобы обеспечить их полезность, честность и безопасность.
Оптимизация функций вознаграждения
Одной из основных проблем в RLHF является оптимизация функций вознаграждения, используемых в обучении с подкреплением. Традиционные методы включают сложные, многоэтапные процессы, требующие значительных вычислительных ресурсов и могут привести к субоптимальной производительности из-за расхождений между метриками обучения и вывода. Существующие исследования включают прямую оптимизацию предпочтений (DPO), IPO, KTO и ORPO, которые предлагают вариации обработки данных предпочтений и оптимизации без моделей-справок. Эти подходы направлены на упрощение RLHF путем решения сложностей и неэффективностей, присущих традиционным методам, предоставляя более эффективные и масштабируемые решения для выравнивания больших языковых моделей с обратной связью от людей.
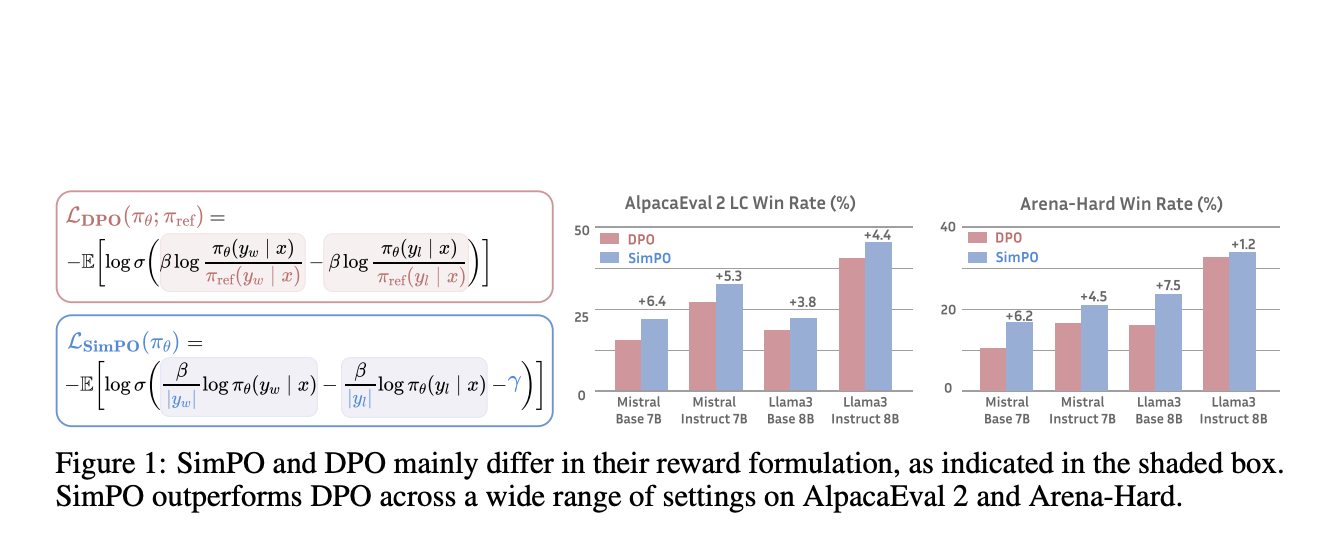
SimPO: новый подход к оптимизации предпочтений
SimPO представляет собой более простой и эффективный подход к оптимизации предпочтений. Он использует среднюю логарифмическую вероятность последовательности в качестве неявного вознаграждения, лучше соответствуя генерации модели и устраняя необходимость в модели-справке. SimPO также включает целевую границу вознаграждения для обеспечения значительной разницы между выигрышными и проигрышными ответами, что улучшает стабильность производительности.
Практическая значимость SimPO
SimPO значительно превосходит DPO и его последние варианты на различных тренировочных установках, включая базовые и инструкционно настроенные модели. Это подтверждается результатами на бенчмарке AlpacaEval 2 и Arena-Hard, где SimPO показал впечатляющую производительность. Его эффективность также проявляется в более эффективном использовании предпочтительных данных, что приводит к лучшей модели политики, способной последовательно генерировать качественные ответы.
Заключение
SimPO представляет собой значительное совершенствование в области оптимизации предпочтений для RLHF, предлагая более простой и эффективный метод, который последовательно обеспечивает превосходную производительность. Этот подход решает ключевые проблемы в области, предоставляя надежное решение для улучшения качества больших языковых моделей.
«`

























