Использование SynSUM для ИИ в здравоохранении
Практические решения и ценность
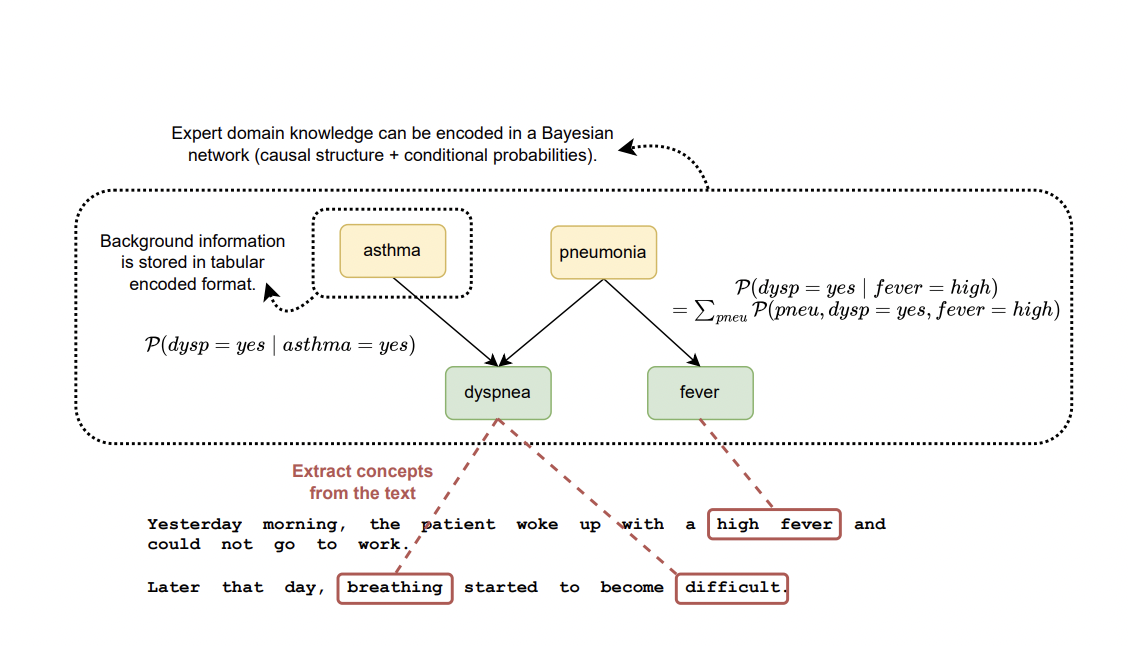
Электронные медицинские записи (EHR) содержат множество информации, объединяя структурированные таблицы и неструктурированные клинические заметки. Это ценный ресурс, на основе которого обучаются системы клинической поддержки принятия решений и автоматизируются процессы диагностики и планирования лечения.
Существующие методы не полностью используют доступные медицинские знания для сокрытия этого разрыва. Два дополнительных источника информации — это табличные признаки, уже закодированные в EHR, и медицинские знания, структурированные как байесовская сеть, способны улучшить CIE. Это помогает связать закодированную фоновую информацию с концепциями, извлеченными из текста.
Исследователи из IDLab, Департамента информационных технологий университета Гента — imec Гента, Бельгия, и Департамента общественного здравоохранения и первичного ухода университета Гента, Бельгия, предложили бенчмарк SynSUM, который является синтетическим набором данных, связывающим неструктурированные клинические заметки с структурированными фоновыми переменными.
Предложенный метод SynSUM использует четыре различных подхода для прогнозирования симптомов на основе клинических данных:
1. BN-tab: Байесовская сеть с заранее определенной причинной структурой.
2. XGBoost-tab: Классификатор XGBoost, обученный для каждого симптома под тремя различными настройками доказательств.
3. Neural-text: Нейронный классификатор, обрабатывающий только текстовый ввод.
4. Neural-text-tab: Расширение подхода neural-text, использующее табличные переменные с текстовыми вложениями.
В заключение, исследователи представили набор данных SynSUM, который предлагает множество потенциальных применений в исследованиях в области здравоохранения. Его основная цель — улучшить техники извлечения клинической информации для объединения табличных фоновых переменных.

























