Введение нового бенчмарка TabReD от Yandex для табличного машинного обучения
В последние годы исследования в области табличного машинного обучения стремительно развиваются. Однако они по-прежнему представляют значительные вызовы для исследователей и практиков. Традиционные академические бенчмарки для табличного машинного обучения не полностью отражают сложности, с которыми сталкиваются в реальных промышленных приложениях.
Практические решения и ценность
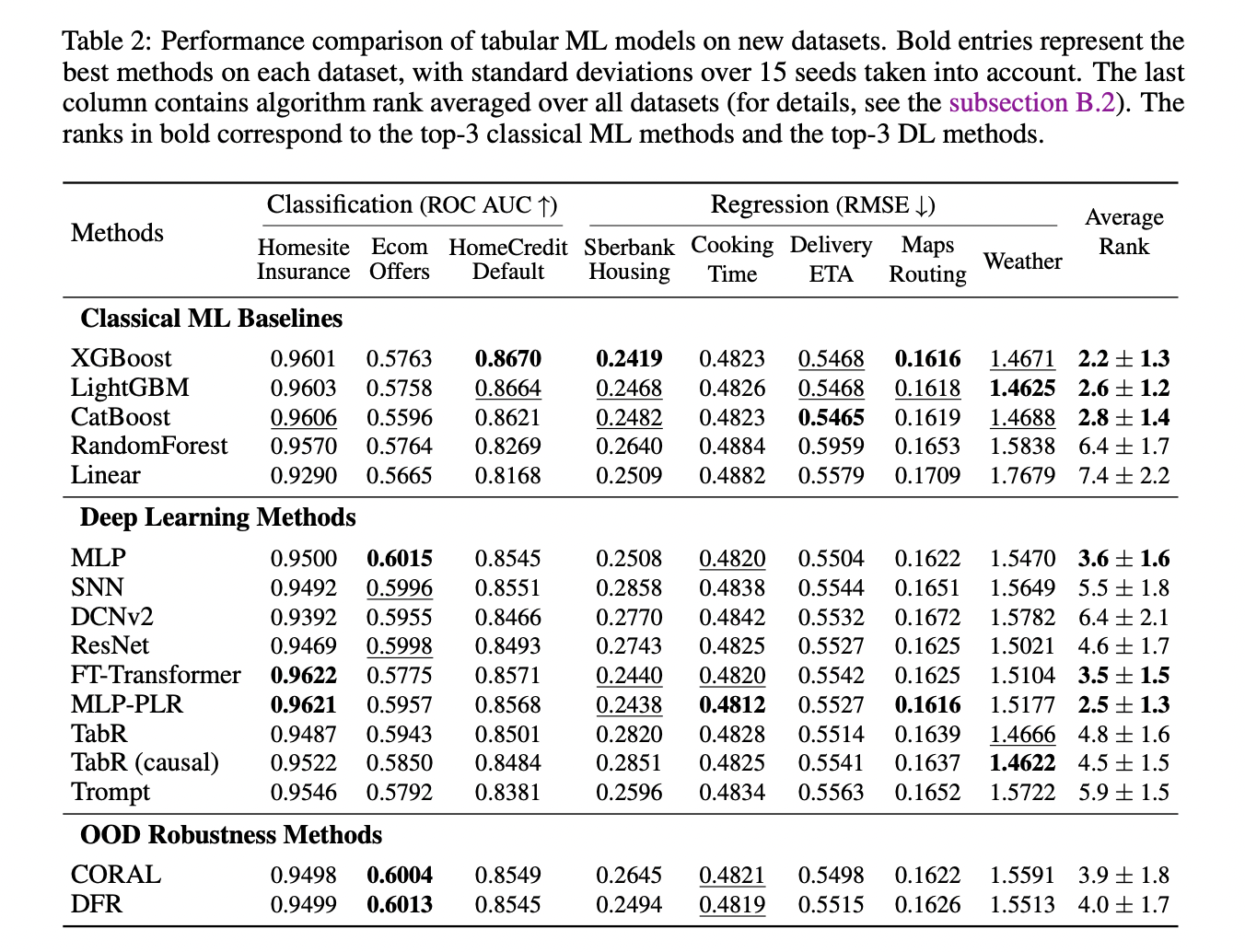
Для решения этих проблем исследователи из Yandex и HSE University представили TabReD, новый бенчмарк, разработанный для отражения промышленных приложений табличных данных. TabReD состоит из восьми наборов данных из реальных приложений в областях финансов, доставки еды и недвижимости. Код и наборы данных были сделаны общедоступными на GitHub.
Для создания TabReD исследователи использовали наборы данных из соревнований Kaggle и приложений машинного обучения Yandex. Они удостоверились, что наборы данных являются табличными, соответствуют практикам промышленной инженерии признаков и исключили наборы данных с утечкой информации. Также они обеспечили наличие временных меток и достаточное количество выборок для разделения по времени, исключив наборы данных без будущих экземпляров.
Восьмой набор данных в бенчмарке TabReD включает следующее:
- Homesite Insurance
- Ecom Offers
- HomeCredit Default
- Sberbank Housing
- Cooking Time
- Delivery ETA
- Maps Routing
- Weather
Эти наборы данных обладают двумя ключевыми практическими свойствами, часто отсутствующими в академических бенчмарках. Во-первых, они разделены на обучающие, валидационные и тестовые наборы данных на основе временных меток, что существенно для точной оценки. Во-вторых, они включают больше признаков благодаря обширным усилиям по сбору данных и инженерии признаков.
Исследователи провели тестирование недавних методов глубокого обучения для табличных данных на бенчмарке TabReD, чтобы оценить их производительность с разбиением данных по времени и дополнительными признаками. Они пришли к выводу, что разделение данных по времени имеет решающее значение для правильной оценки. Результаты выявили MLP с эмбеддингами для непрерывных признаков как простую, но эффективную базовую модель глубокого обучения, в то время как более сложные модели показали менее впечатляющую производительность в этом контексте.
TabReD устраняет разрыв между академическими исследованиями и промышленным применением в табличном машинном обучении. Он позволяет исследователям разрабатывать и оценивать модели, которые более вероятно будут успешно работать в производственных средах, предоставляя бенчмарк, который тесно соответствует реальным сценариям. Это критически важно для упрощенного принятия новых исследовательских результатов в практических приложениях.
Бенчмарк TabReD задает направление для исследования дополнительных аспектов, таких как непрерывное обучение, учет постепенных временных изменений и улучшение техник выбора и инженерии признаков. Он также подчеркивает необходимость разработки надежных протоколов оценки для более точной оценки реальной производительности моделей машинного обучения в динамичных реальных средах.
Вся заслуга за это исследование принадлежит исследователям этого проекта.
Если вы хотите узнать больше о бенчмарке TabReD, обратитесь к GitHub.

























